Renku wurde vom Swiss Data Science Center als Web-Plattform (Renkulab) und Terminal (Renku Client) entwickelt, um zu ermöglichen, kollaborativ Daten zu generieren, bearbeiten, speichern und zu teilen. Zudem können Code, ganze Workflows und virtuelle Maschinen verwaltet werden.
In Renkulab werden direkt im Browser Juypter Lab oder RStudio Sessions gestartet, die aus Docker Containern laufen. Notwendige Packages und Libraries werden ganz einfach über ein Requirements-File installiert. Um die Daten nachvollziehbar und sicher zu speichern, werden diese über ein integriertes GitLab verwaltet. Im Renku CLI, dem eigenen Terminal, können aber auch verschiedene renku commands verwendet werden, um Daten zu speichern, auf Gitlab zu pushen, und vieles mehr.
Für einen einfachen Anwendungsfall kann Renkulab auch von Anfänger*innen verwendet werden, die sich v.a. die mühsame Installation mehrerer Programmiersprachen und Tools ersparen möchten. Erfahrenere Anwender*innen wählen zwischen verschiedenen Programmiersprachen, arbeiten direkt mit git commands, schreiben eigene Skripts oder stellen sie in sogenannten renku-Workflows zusammen.
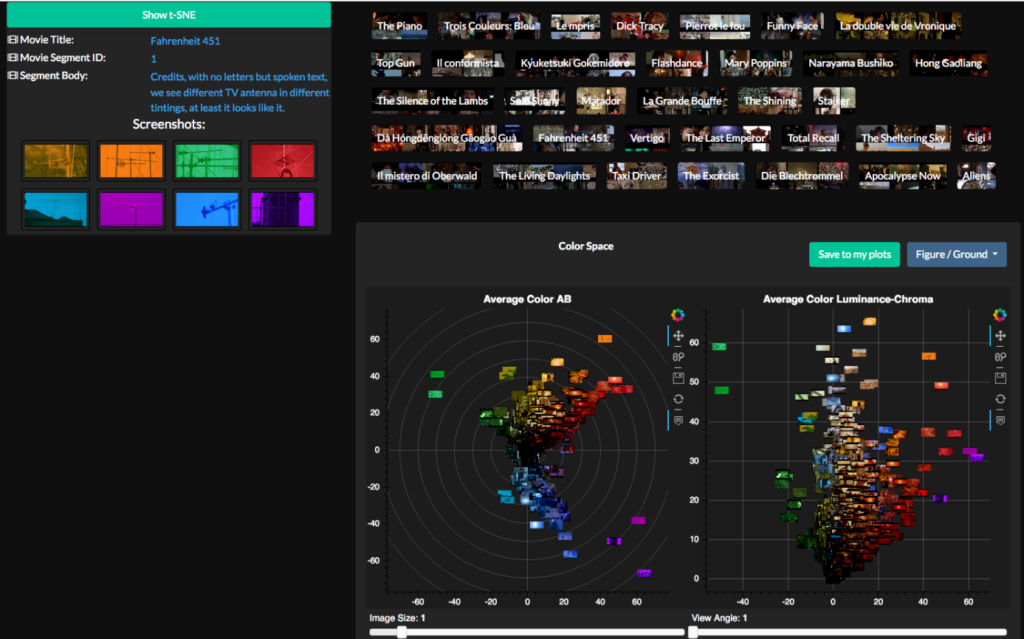
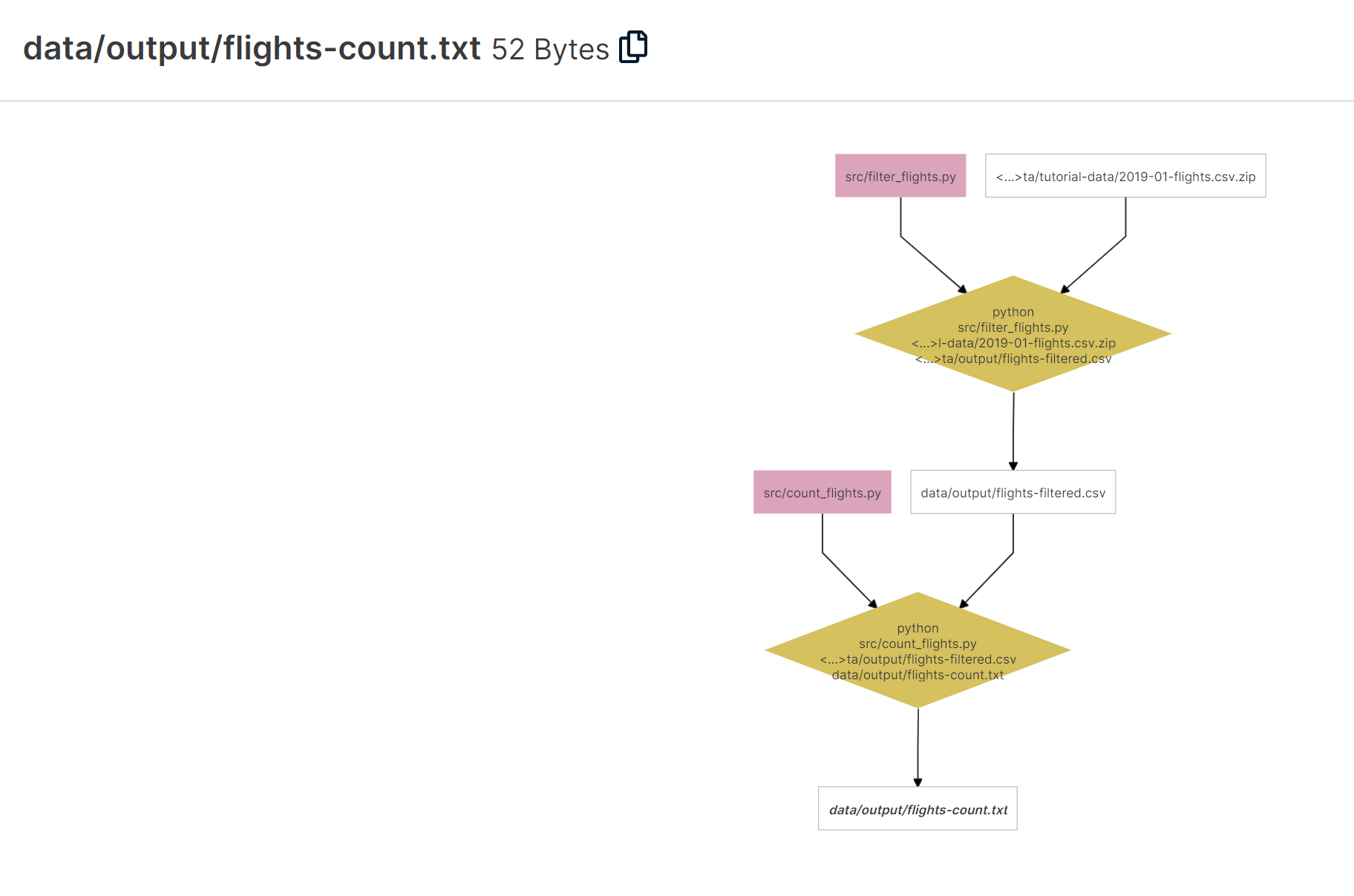
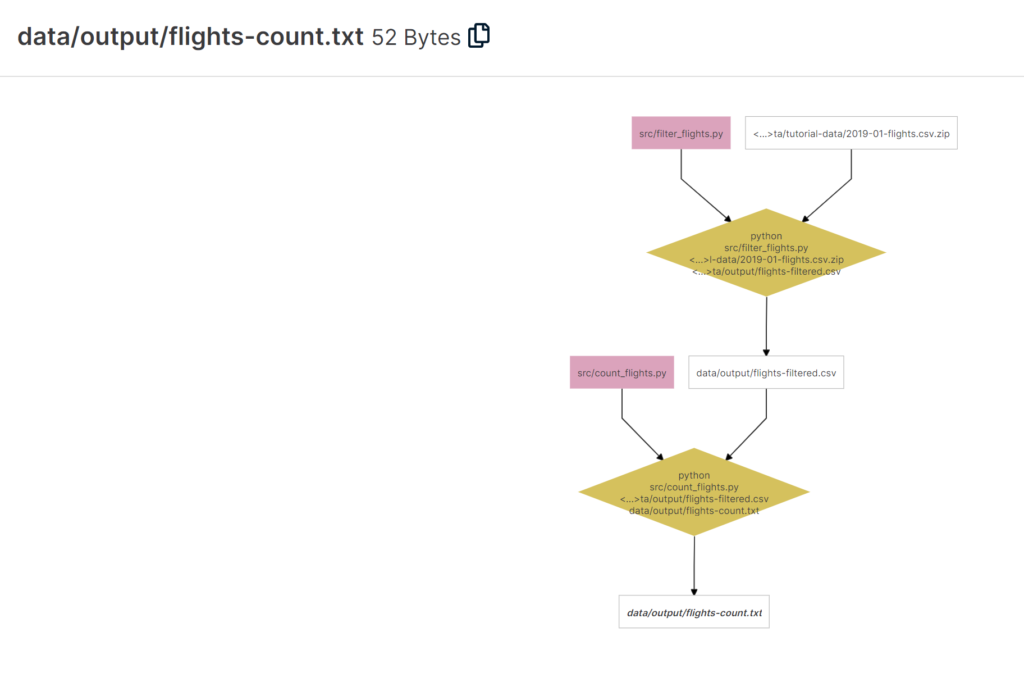
Ein grosser Vorteil von Renkulab ist ausserdem der Knowledge Graph. Was ist das und wozu dient er? Angenommen, die verwendeten Daten stammen von einer Online-Quelle, wurden in mehreren Schritten durch verschiedene Skripts bearbeitet und generieren nun den gewünschten Output. Wie oft kommt es vor, dass man nicht mehr reproduzieren kann, wie dieser Output genau entstanden ist, weil man verschiedene Ansätze ausprobiert hat? Der Knowledge Graph löst nun genau dieses Problem, indem er in einem Diagramm jeden Verarbeitungsschritt visualisiert und den Output dadurch nachvollziehbar und reproduzierbar macht.
Gerade für Einführungen in die Programmierung, Gruppenarbeiten in einem Seminar oder auch den Austausch für eine Forschungsgruppe ist Renku sehr gut geeignet.
Ein Tutorial führt Klick für Klick durch die Möglichkeiten von Renku – es lohnt sich, das auszuprobieren!
Für jede Session wird die Rechenpower und die Umgebung gewählt.Jupyter Lab läuft innerhalb eines Gitlab Accounts.Ein Jupyter Notebook ermöglicht es, schön lesbare Tutorials oder Aufgaben mit Python zu erstellen.Auch eigene Python Skripts können natürlich verwendet werden.Der Knowledge Graph visualisiert nicht nur die Datenherkunft, sondern auch die einzelnen Verarbeitungsschritte.
Das neue Text Crunching Center (TCC) hilft bei Textanalysen und bei Fragen wie: Wie komme ich zu meinen Daten? Wie muss ich sie für meine Forschungsfrage aufbereiten, oder – welche Fragen kann ich an meine Daten stellen? Angesiedelt am Institut für Computerlinguistik und konzipiert als Dienstleistungszentrum – wir hören in diesem Beitrag, für wen das TCC gedacht ist und welche Dienstleistungen angeboten werden.
Bitte stellen Sie sich vor!
[Tilia Ellendorff, TE]: Mein Name ist Tilia Ellendorff. Ursprünglich habe ich Grundschullehramt mit den Fächern Englisch und Deutsch studiert an der Universität Paderborn. Anschliessend habe ich mich aber entschlossen, mich auf Linguistik und Computerlinguistik zu konzentrieren – zunächst mit einem Bachelor in Linguistik, dann mit einem Internationalen Masterstudium in Computerlinguistik in Wolverhampton (GB) und Faro (P), über Erasmus Mundus. Schliesslich bin ich für das Doktorat in Computerlinguistik nach Zürich gekommen. Mein Thema war Biomedical Text Mining – in meinem Projekt ging es darum, in medizinischen Publikationen die Beziehung zwischen ätiologischen, also auslösenden, Faktoren von psychiatrischen Erkrankungen zu extrahieren. Hier besteht nämlich das Problem, dass es unmöglich ist, die gesamte Literatur auf diesem Gebiet zu lesen. Es ist schwierig, so einen Überblick über alle Faktoren zu gewinnen. Ich habe dazu ein System gebaut, das dies unterstützt und automatisch aus den Texten extrahiert.
[Gerold Schneider, GS]: Ich habe Englische Literatur- und Sprachwissenschaft und Computerlinguistik an der Universität Zürich studiert. Während des Doktorats habe ich einen syntaktischen Parser für Englisch entwickelt. Es ist ein System, das eine syntaktische Analyse eines Texts liefert: Was ist das Subjekt, was das Objekt, welches die untergeordneten Sätze, etc. Mit der Anwendung dieses Tools bin ich schliesslich in das Gebiet des Text Minings gelangt. Zunächst habe ich das auch zu Fachliteratur im biomedizinischen Bereich angewendet. Die gleichen Methoden konnte ich später in weiteren Disziplinen verwenden, z.B. in Projekten mit dem Institut für Politikwissenschaft im NCCR Democracy zu Demokratieforschung, oder auch in einem Projekt zu Protestforschung. Dabei geht es ja nicht nur um eine Faktensammlung, sondern meist um Meinungen, Stimmungen oder Assoziationen, die aus den Medien extrahiert werden müssen: Gerade da braucht man statistische Methoden, mit logikbasierten stösst man nur auf Widersprüche. Somit sind auch die Methoden des maschinellen Lernens unerlässlich. Die Daten und Ergebnisse müssen zum Schluss aber auch interpretiert werden können – sonst nützt die Datensammlung nicht viel. Mein breiter Hintergrund ist hier sicher von Vorteil – ich sehe mich auch als Brückenbauer zwischen Disziplinen.
Vielen Dank für die Vorstellung – wie ist denn nun das Text Crunching Center entstanden?
[GS] Entstanden ist das Text Crunching Center dadurch, dass das Institut für Computerlinguistik bzw. Martin Volk inzwischen so viele Anfragen im Gebiet Text Mining und Textanalyse erhält, dass es nicht mehr länger möglich ist, diese alle selbst zu bearbeiten.
Das Text Crunching Center bietet in diesem Gebiet Dienstleistungen an: Bei allem, was mit Text Mining, Sentimentanalyse, Textanalyse im Allgemeinen – generell mit Methoden der Digital Humanities oder Machine Translation – zu tun hat, können wir Projekte unterstützen. Auch allgemeine Unterstützung für Digitalisierungsprozesse oder Textverarbeitung wie OCR, aber auch Beratung zu Tools, Software oder Best Practices bieten wir an. Wir helfen ebenfalls gerne beim Schreiben von Projektanträgen, geben Coaching und Unterricht in der Textanalyse, oder können fertige (Software-)Lösungen anbieten.
[TE] Wir sind die Ansprechpartner für alle, die in ihren Projekten mit viel Text umgehen müssen, das technische Knowhow aber nicht haben und nicht genau wissen, wo sie anfangen sollen. Man kann z.B. zu uns kommen, wenn man einfach Text vor sich hat und eine Idee braucht, was man damit mit der Maschine alles anfangen könnte.
Könnten Sie mir ein konkretes Beispiel einer Anfrage geben – wie muss man sich den Ablauf vorstellen, wenn man auf Sie zukommt?
[TE] Wenn z.B. jemand aus einem bestimmten Forschungsgebiet untersuchen möchte, was der öffentliche Diskurs zu einem Thema ist – nehmen wir mal das Thema «Ernährung». Dazu möchten sie dann gerne Social Media Daten auswerten, die technische Umsetzung ist gehört aber nicht zu ihrem Fachgebiet. In dem Fall kann man zu uns gelangen und wir beraten in einem ersten Schritt: Wir klären die Fragen, wie man überhaupt an Daten gelangen kann, was man mit den Daten machen könnte. Es kann so weit gehen, dass wir einen Prototypen erstellen, mit dem sie dann direkt ihre Daten auswerten und Forschungsergebnisse erhalten können.
Welche konkreten Möglichkeiten würden Sie in den Personen in diesem Beispiel vorschlagen und wie würden sie es umsetzen?
[GS] In diesem konkreten Beispiel haben wir Twitter-Daten mit Hilfe von Text Mining gesammelt und ein Coaching angeboten. Die R Skripts haben wir ebenfalls geschrieben, die Personen aber zusätzlich so weit gecoacht, dass sie diese schliesslich selbst anwenden konnten. Die über das Text Mining erhaltenen Daten werden mit den Skripts exploriert und verschiedene Outputs generiert. Dabei haben wir «klassische» Digital Humanities Methoden angewendet wie z.B. Distributionelle Semantik, Topic Modeling, oder auch analysiert, wie in den Tweets bestimmte linguistische Merkmale gebraucht werden.
[TE] Es kommt immer auf die Kunden darauf an: In diesem Beispiel wollten die Kunden die Anwendung gerne selber lernen. Wenn sie dafür aber keine Zeit oder kein Interesse daran gehabt hätten, hätten wir auch alles selbst implementieren können: Also das fertige System oder die aufbereiteten Daten.
[GS] Ein Produkt, das dabei entstanden ist, ist eine «konzeptuelle Karte» von Bier, Cidre und Wein. Es ist eine semantische Karte, in der ähnliche Konzepte näher beieinander liegen als Konzepte, die inhaltlich weiter voneinander entfernt sind. Rund um den Cidre liegen beispielsweise die Begriffe «Äpfel», «Jahreszeit», «Wärme» usw. Man sieht auch, dass die Essenskultur mit «dinner», «cooking», etc. viel näher am Konzept «Wein» liegt als bei «Bier» oder «Cidre». Solche automatisch erstellten Karten vereinfachen stark, sind aber anschaulich und gut interpretierbar, deshalb zeigen wir sie als ein Beispiel unter vielen.
Eine ähnliche Karte etwa entstand in einem anderen Projekt aufgrund von Daten ausgewählter Reden von Barack Obama und Donald Trump. Barack Obama spricht etwa mehr von «opportunity» oder «education», während Donald Trump davon eher weiter weg ist und eher über China und Deals spricht, und wer ihm alle angerufen haben. «Peace and Prosperity» als Vision versprechen natürlich beide.
Nun rein technisch gefragt – wie entsteht so eine konzeptuelle Karte? Die Verbindungen stellen die Distanzen zwischen den Konzepten dar, nehme ich an – mit welcher Methode bestimmen Sie denn die Ähnlichkeiten?
[GS] Es handelt sich um eine Methode der distributionellen Semantik: Man lernt aus dem Kontext. D.h. dass Wörter, die einen ähnlichen Kontext haben, auch semantisch ähnlich sind. Gerade bei grossen Textmengen führt so ein Ansatz zu guten Ergebnissen. Es gibt da verschiedene Methoden, um dies zu bestimmen – gemeinsam ist ihnen jedoch der kontextuelle Ansatz.
In diesem konkreten Beispiel wurde mit Kernel Density Estimation gearbeitet. Man zerlegt dafür den Korpus zunächst in kleine Teile – hier waren es etwas 2000. Für jedes Wort prüft man dann, wie das gemeinsame Auftreten in den 2000 «Teilen» ist. Wörter, die sehr häufig miteinander auftreten, kommen dann das Modell. Dabei werden nicht die absoluten Zahlen verwendet, sondern Kernel-Funktionen gleichen die Zahlen etwas aus. Daraus kann schliesslich die Distanz zwischen den einzelnen Konzepten berechnet werden. In diesem Prozess entsteht ein sehr hochdimensionales Gebäude, das für die Visualisierung auf 2D reduziert werden muss, um es plotten zu können. Da dies immer eine Vereinfachung und Approximierung ist, braucht es immer die Interpretation.
Wie wichtig ist es für Ihre Aufgabe, dass Sie einen breiten disziplinären Hintergrund haben?
[TE] Man darf nicht denken, dass die Texttechnologie das «Wunderheilmittel» für alle Probleme ist. In einer Beratung geben wir immer eine realistische Einschätzung darüber ab, was möglich ist und was nicht.
Daher ist die Frage sehr relevant. Man muss einen gemeinsamen Weg zwischen der computerlinguistischen und der inhaltlichen Seite finden. Es ist wichtig, dass wir beide durch unseren Werdegang viele Disziplinen abdecken und schon in vielen verschiedenen Bereichen mitgearbeitet haben.
Gerade in einem Projekt aus der Biomedizin, in dem es darum ging, welche Auswirkungen bestimmte Chemikalien auf gewisse Proteine haben, hat mein biologisches Wissen aus dem Biologie-Leistungskurs und einem Semester Studium sehr geholfen. Als Laie würde man diese Texte überhaupt nicht verstehen, deshalb könnte man auch keine geeignete Analyse entwerfen. Insbesondere auch auf der Ebene der Fehleranalyse ist das Disziplinen-Wissen wichtig: Möchte man herausfinden, warum das entwickelte System in manchen Fällen nicht funktioniert hat, hat man ohne disziplinäres Wissen wenig Chancen.
Deshalb ist es wichtig, dass wir realistische Einschätzungen darüber abgeben können, was umsetzbar ist – manche Fragen sind aus computerlinguistischer Sicht schlicht nicht auf die Schnelle implementierbar.
[GS] Dennoch können oft neue Einsichten generiert werden, oder auch nur die Bestätigung der eigenen Hypothesen aus einer neuen Perspektive… Die datengetriebenen Ansätze ermöglichen auch eine neue Art der Exploration: Man überprüft nicht nur eine gegebene Hypothese, sondern kann aus der Datenanalyse neue Hypothesen generieren, indem man Strukturen und Muster in den Daten erkennt.
Hier hat sich bei mir ein Kreis geschlossen: Aus der Literaturwissenschaft kenne ich das explorative Vorgehen sehr gut. Dagegen ist ein rein computerlinguistisches Vorgehen schon sehr anders. Mit Ansätzen der Digital Humanities kommt nun wieder etwas Spielerisches in die Technologie zurück. Die Verbindung von beidem erlaubt einen holistischeren Blick auf die Daten.
Wie würden Sie denn Digital Humanities beschreiben?
[GS] Es ist wirklich die Kombination der beiden Ansätze: «Humanities» kann man durchaus wortwörtlich nehmen. Gerade in der Linguistik ist damit auch ein Traum wahr geworden, wenn man an Ferdinand de Saussures Definition von Bedeutung denkt. «La différence», die Bedeutung, ergibt sich nicht daraus, was etwas «ist», sondern was es im Zusammenhang, im Ähnlich-Sein, im «Nicht-genau-gleich-sein» mit anderen Dingen ist. In der Literaturwissenschaft wird dieser Umstand in der Dekonstruktion mit der «différance» von Jacques Derrida wieder aufgenommen. Die distributionale Semantik hat genau das berechenbar gemacht. Es ist zwar einerseits sehr mathematisch, andererseits ist für mich dieser spielerische Zugang sehr wichtig.
Die genaue philosophische Definition von Digital Humanities ist für mich dagegen nicht so wichtig: Doch die Möglichkeiten, die sich mit den digitalen Methoden ergeben – die sind toll und so viel besser geworden.
[TE] Die Humanities, die bisher vielleicht noch nicht so digital unterwegs waren, geraten momentan auch etwas unter Druck, etwas Digitales zu benutzen…
Mein Eindruck war bisher nicht nur der eines «Müssens», sondern auch eines «Wollens» – doch der Einstieg in die Methodik ist einfach sehr schwierig, die Schwelle sehr hoch.
[TE] … und gerade hier können wir einen sehr sanften Einstieg mit unseren Beratungen bieten: Wenn jemand noch gar keine Erfahrung hat, aber ein gewisses Interesse vorhanden ist. So muss niemand Angst vor der Technologie haben – wir begleiten das Projekt und machen es für die Kunden verständlich.
[GS] Aber auch Kunden, die schon ein Vorwissen haben und bereits etwas programmieren können, können wir immer weiterhelfen…
Gilt Ihr Angebot nur für Lehrende und Forschende oder auch für Studierende?
[TE] Das Angebot gilt für alle, auch für externe Firmen. Für wissenschaftliche Projekte haben wir aber natürlich andere, günstigere Tarife.
[GS] Die Services werden zum Selbstkostenpreis angeboten. Ein Brainstorming, d.h. ein Einstiegsgespräch können wir sogar kostenlos anbieten. Auch für die anschliessende Beratungs- oder Entwicklungsarbeit verlangen wir keine überteuerten Preise. Für unser Weiterbestehen müssen wir allerdings eine gewisse Eigenfinanzierung erreichen.
Wo soll das Text Crunching Center in einigen Jahren stehen?
[TE] Natürlich möchten wir personell noch wachsen können… Wir bilden uns dauernd weiter, um state-of-the-art-Technologien anbieten zu können. Die Qualität der Beratung soll sehr hoch sein – das wünschen wir uns.
[GS] … und wir wollen die digitale Revolution unterstützen, Workshops anbieten, das Zusammenarbeiten mit dem LiRI oder mit Einzeldisziplinen verstärken. Letztlich können alle von der Zusammenarbeit profitieren, indem man voneinander lernt und Best Practices und Standardabläufe für gewisse Fragestellungen entwickelt. Auch die Vernetzung ist ein wichtiger Aspekt – wir können helfen, für ein bestimmtes Thema die richtigen Experten hier an der UZH zu finden.
Ich drücke Ihnen die Daumen! Vielen Dank für Ihr Gespräch!
In diesem Beitrag unserer Reihe zu «Digital Humanities an der Philosophischen Fakultät» hören wir von Christine Grundig, wissenschaftlicher Mitarbeiterin am Kunsthistorischen Institut, über ihre Lehrerfahrungen beim Unterricht von digitalen Methoden. In der Reihe geben Lehrende und Forschende der PhF uns einen Einblick in Forschungsprojekte und Methoden «ihrer» Digital Humanities und zeigen uns, welche Technologien in ihrer Disziplin zum Einsatz kommen.
Wer sind Sie – bitte stellen Sie sich vor!
Mein Name ist Christine Grundig, ich habe Staatsexamen für Deutsch, Englisch und Erziehungswissenschaften für das Lehramt an Gymnasien studiert und den Magister Artium an der Universität Würzburg gemacht. Nun schliesse ich gerade meine germanistische Promotion ab. Ich arbeitete v.a. in Projekten, die sich mit digitalen Editionen beschäftigten und habe so Kompetenzen im Bereich der Digital Humanities erworben. Seit Oktober 2017 bin ich als «Digital Humanities Spezialistin» am Kunsthistorischen Institut der Universität Zürich tätig [lacht] – bitte lassen Sie mich diesen Begriff jetzt nicht definieren! Als wissenschaftliche Mitarbeiterin arbeite ich im SNF-Projekt zu Heinrich Wölfflin am Lehrstuhl von Prof. Dr. Tristan Weddigen. Als Dozentin unterrichte ich in meinem Lehrprojekt «Digitale Bildwissenschaften/Digital Visual Studies» bzw. «Digital Skills», das von swissuniversities im Rahmen des Projekts «P8-Stärkung von Digital Skills in der Lehre» 2019-2020 gefördert wird.
Könnten Sie uns diese beiden Projekte kurz vorstellen?
Gegenstand unseres Editionsprojekts ist eine kritisch-kommentierte Edition sämtlicher Publikationen Heinrich Wölfflins – er ist für Kunsthistorikerinnen und Kunsthistoriker eine der zentralen Figuren. Wir haben das grosse Glück, dass wir in der Nähe seiner Wirkungsorte tätig sind – einen Teil seines Nachlasses (Foto- und Diasammlung, Bibliothek, Möbel) hat er dem Kunsthistorischen Institut vermacht. Durch die Nähe zur Universität Basel, in der ein Grossteil des archivalischen Nachlasses liegt (Notizhefte, Manuskripte, Korrespondenz), ist es uns möglich, mit bisher unveröffentlichtem Archivmaterial zu arbeiten. Dies war anderen Editionen bisher nicht oder nicht in diesem Masse möglich.
Es entsteht eine klassische Printedition (die ersten Bände sind bereits publiziert), daneben aber auch eine digitale Edition, die sich an aktuellen Technologien und Standards der Digital Humanities orientiert. Das Material wird in der digitalen Edition im Rahmen eines eigenen Wölfflin-Portals nachhaltig erschlossen, einer Forschungsplattform, die Kontextualisierungen möglich macht und v.a. auch Schnittstellen zu anderen Projekten bietet. Dazu werden die Bände, die bereits im Print erschienen sind in XML/TEI konvertiert, um sie «für das Internet fähig zu machen». Das Versehen mit Referenz- bzw. Normdaten für Werke, Personen, Objekte, Orte, historische Termini und bibliographische Angaben ist ein zentrales Anliegen. Das Portal wird auch Bildmaterial mit hochauflösenden Scans nach IIIF-Standard zugänglich machen, zudem Archivmaterial, das zum Teil mit Tools wie Transkribus oder OCR4all erarbeitet wird.
Wir werden eine semantisch angereicherte Edition bereitstellen, die aus Linked Open Data (LOD) besteht. So können wir einen möglichst grossen Nutzen für die Forschungsgemeinschaft erzielen, weil die Daten dadurch nachhaltig sind und Interoperabilität gewährleistet ist.
Und was beinhaltet das Projekt zu «Digital Skills»?
Wir schlugen im Rahmen von «P8» eine «Einführung in digitale Methoden in der Kunstgeschichte» für Bachelor- und Masterstudierende vor. Ursprünglich war der Fokus eher auf den Bildwissenschaften, doch ich merkte in den ersten Sitzungen, dass ich «ganz vorne anfangen» und den Fokus auf «digital skills» im Allgemeinen legen muss. Es mangelt an Grundkompetenzen der Studierenden im Umgang mit digitalen Methoden.
Konkret besprechen wir im Kurs zunächst, was Digital Humanities überhaupt sind, und ganz wichtig, was die Studierenden eigentlich darunter verstehen. Ich möchte wissen, in welchen Bereichen sie schon mit Tools oder digitalen Methoden gearbeitet haben. Jede/Jeder hat z.B. Datenbanken genutzt oder in Katalogen recherchiert, aber meist wissen sie gar nicht, dass das Datenbanken sind oder was genau dahintersteckt.
Man muss auf einer ganz grundlegenden Ebene aufklären und zeigen, welche Möglichkeiten es in einer Disziplin gibt, mit digitalen Methoden zu arbeiten. Wir behandeln Datenbanken, digitale Editionen, Bilderkennung und Bildannotation, IIIF-Formate oder auch Texterkennung mit OCR.
Wichtig ist mir dabei, praxis- bzw. berufsorientiert vorzugehen, wenn wir digitale Werkzeuge ausprobieren: Die Studierenden sollen ganz konkret mit Tools wie z.B. Transkribus arbeiten, weil sie nur dann die Hemmschwelle überwinden, die Angst davor verlieren. Viele denken sich nämlich, «Ich bin keine Informatikerin, kein Informatiker, ich kann das nicht». Wenn man diese Barriere überwindet, kann es durchaus vorkommen, dass Studierende sich vielleicht sogar an eigenen kleinen (Python-)Skripts versuchen, vielleicht mit etwas Unterstützung aus der Informatik oder Computerlinguistik, aber alleine die Tatsache, dass sie sich damit auseinandersetzen – das ist ganz zentral und erfreulich für mich.
Was kann man mit Transkribus oder OCR4all denn konkret machen?
Wenn wir mit Handschriften oder historischen Drucken arbeiten, liegen uns Scans davon vor. Wir schauen dann, wie man diese digital aufbereiten kann: Zeilen segmentieren, einzelne Text- und Bildbereiche voneinander trennen usw. Dafür haben wir z.B. das Segmentierungstool Larex, das zu OCR4all gehört, und das das Layout analysiert: Dies bedeutet, Seiten zu segmentieren, die wir danach transkribieren können. Über die Textdaten, die wir durch die Transkription erhalten, lassen wir «Trainings», also Machine Learning-Algorithmen laufen. Der Output ist zunächst noch fehlerhaft; er wird von Hand korrigiert, um diese optimierten Daten wieder «durch die Maschine laufen zu lassen», sie so weiter anzulernen und dadurch das Ergebnis zu verbessern. Auf diese Weise können selbst Kurrent-Handschriften wie die von Heinrich Wölfflin automatisch erkannt werden, aber auch z.B. Drucke mit Fraktur- oder Antiqua-Schrift, für die es bereits sehr gute Modelle gibt. Diese kommen meist aus dem germanistischen Bereich, stehen aber allen zur Verfügung. So können wir interdisziplinär arbeiten, auf den Modellen aufbauen und die Daten austauschen, sie weiter trainieren.
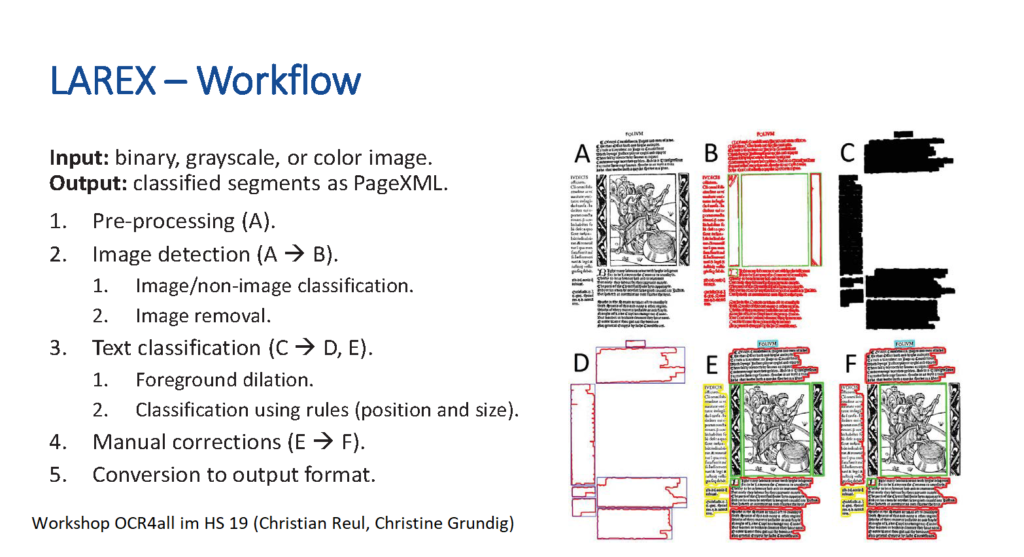
Beispiel einer Layout Segmentierung mit Larex
Ein Ausschnitt aus der Arbeit mit Transkribus
Wenn Sie sagen, die Hemmschwelle muss überwunden werden – wie gehen Sie da im Unterricht vor, wenn Sie z.B. Daten vor sich haben?
In der Einführung haben wir uns zunächst mit Datenbanken beschäftigt, z.B. was unterscheidet eine Graphdatenbank von einer relationalen Datenbank, welche Datenmodelle stecken dahinter?
In der Hoffnung, dass das Lehrprojekt weitergeführt werden kann, möchte ich unbedingt mehr Seminare anbieten, die auf dieser Einführung aufbauen und konkrete Themen vertiefen. In diesen Seminaren könnte man dann z.B. Daten modellieren oder eigene Daten erheben. Zu jedem der erwähnten Themenbereiche und Tools könnte man eigene Seminare anbieten, die in die Tiefe gehen.
Dennoch bleibt es wichtig, vorher die Grundlagen zu klären: Was ist eine Auszeichnungssprache wie HTML? Was ist XML? Was ist eine Programmiersprache? Die wenigsten wissen, was eigentlich hinter einer Webseite steckt, die sie im Internet aufrufen.
Würden Sie sagen, dass diese Skills innerhalb der eigenen Disziplin unterrichtet werden sollten oder eher fachübergreifend?
Ich denke, es ist wichtig, zunächst im Kleinen anzufangen und am eigenen Institut zu sehen, wie dort das Gefühl, der Bedarf und das Interesse für digitale Methoden sind. Wollen die Studierenden aus den Kunstwissenschaften so ein Angebot überhaupt besuchen? Ich kann Ihnen sagen: Ja. Ich habe nicht damit gerechnet, so viele Anmeldungen zu bekommen, ich musste jedes Mal einen grösseren Raum buchen.
Da ich selbst keine Kunsthistorikerin bin, sondern Germanistin, steht das Thema Interdisziplinarität sowieso im Fokus des Projekts. Die Methoden kann ich genauso gut in der Kunstgeschichte unterrichten wie in der Germanistik oder sie Historikern, Rechtswissenschaftlern oder Theologen anbieten.
Es ist mir ganz wichtig, dass sich hier ein interdisziplinäres, reziprokes Verhältnis, zunächst an der Philosophischen Fakultät, aber auch darüber hinaus entwickelt. In meiner Zusammenarbeit mit der Digital Society Initiative (DSI), die ein «Studium Digitale» vorbereitet, wird mein Einführungskurs im Herbstsemester als einer von drei Kursen pilotiert. Wir möchten sehen, wie so ein fakultätsübergreifendes Angebot mit einem eher fachorientierten Kurs, der an einem Institut angesiedelt ist, harmoniert. Zusätzlich wird der Kurs auch in der Computerlinguistik oder im Minor «Digital Humanities und Text Mining» crossgelistet.
Für den Kurs ist es sehr effizient, ein ganz heterogenes Studierendenfeld zu haben, weil die Teilnehmenden sich gegenseitig inspirieren, voneinander lernen. Einige Studierende kommen von klassischen geisteswissenschaftlichen Methoden, während andere mehr von den Daten her denken. Da verschiedene Perspektiven zusammenkommen, können ganz neue Fragestellungen entstehen.
Was verstehen Sie unter Digital Humanities?
Ich habe Ihnen dazu etwas vorbereitet: Auf der Seite whatisdigitalhumanities.com wird bei jedem Refresh ein neues Zitat zum Thema angezeigt. Mit diesen Zitaten habe ich auch versucht, meine Studierenden an das Thema heranzuführen und so die Vielseitigkeit und Divergenz deutlich zu machen. Ein gutes Beispiel dafür:
«Using digital tools to research the Humanities or using Humanities methods to research the digital.”
Das ist natürlich sehr pauschal, aber ich glaube, man muss offen sein im Umgang mit digitalen Methoden. Lässt man z.B. über fünf Romane ein Tool laufen, das Named Entity Recognition oder Topic Modeling kann (noch, bevor ich meine Fragestellung habe), dann ergeben sich mit Sicherheit Sachverhalte, mit denen man zu Beginn seiner Recherche nicht gerechnet hat. Letztlich sind das ebenso geisteswissenschaftliche Methoden, nur die Quantität ist anders, die Korpora werden grösser.
Ich denke, die digitalen Methoden unterscheiden sich letztlich gar nicht so sehr von den analogen, meine Arbeit wird durch die Hilfsmittel aber einfacher, schneller, interessanter. Das ist für mich auch der Mehrwert – dass ich grosse Mengen an Texten, Bildern und Daten untersuchen kann.
Was für ein Lehrangebot würden Sie sich wünschen?
Für mich ist es entscheidend ist, dass es auch Kurse im Bereich Digital Humanities gibt, für die keine technischen Voraussetzungen nötig sind, sonst würde man einen sehr grossen Teil der Studierenden verlieren. Deshalb wünsche ich mir ein Lehrangebot, das einerseits Grundbausteine bietet, für die keine technologischen Vorkenntnisse relevant sind. Andererseits braucht es aber auch aufbauende Module, die Themen vertiefen. Z.B. eine Übung zu digitalen Editionen, in der die Studierenden einen Text selbst in TEI konvertieren, ein XML Dokument erstellen, vielleicht sogar eine kleine Visualisierung auf einer Webseite erzeugen. Man muss die Studierenden sukzessive heranführen.
Damit Studierende lernen können, mit Daten umzugehen, bräuchte es eigentlich auch ein wenig Infrastruktur, z.B. Webserver oder Datenbanken, die über Server zugänglich sind, nicht?
Ja, das fehlt auf jeden Fall noch. Ich hoffe, dass sich so etwas in einigen Semestern etablieren lässt. Ursprünglich war auch meine Idee für den Kurs, zusammen mit den Studierenden z.B. die EasyDB des Kunsthistorischen Instituts zu nutzen und dort selbst Bilder einzuspeisen, mit Metadaten zu versehen usw. Oder wenn Studierende in einer Arbeit eine kleine Applikation entwickeln – da muss man sich überlegen, wo man diese Daten langfristig ablegt, veröffentlicht und somit nachnutzbar macht.
Möchten Sie noch etwas ansprechen, haben wir ein Thema nicht erwähnt?
Die Evaluationen der Lehrveranstaltung haben deutlich gemacht, dass es den dringenden Bedarf und den Wunsch seitens der Studierenden gibt, dieses Angebot wahrzunehmen und auszubauen.
Die Corona-Krise zeigte, wie wichtig es ist, dass man sein Lehrangebot flexibel anpassen kann. Natürlich fällt das einem Kurs wie meinem, der auf digitale Methoden abzielt wesentlich leichter, die Inhalte auch digital zu vermitteln. Viel Arbeit im laufenden Betrieb war es dennoch – das habe ich aber sehr gern in Kauf genommen.
Es geht nicht nur um digitale Forschungsmethoden, sondern eben auch um digitale Lehrformen. Es ist nicht nur die Frage, welches Konferenztool sich besser eignet, sondern auch, wo ich meine Studierenden «abhole», wie ich sie motivieren kann, zu Hause digital zu arbeiten und sie jede Woche trotzdem das Seminar online besuchen. Ich war begeistert von meinem «Corona-Kurs» und dem Ablauf im letzten Semester – das hat so gut funktioniert, es ging nichts verloren.
Man muss die Krise jetzt als Chance sehen, dieses Angebot zu erweitern. Im Herbstsemester werde ich, wenn möglich, eine Blended Learning Form wählen. Das war ursprünglich gar nicht so angedacht. Doch wir haben im Frühjahrssemester so viel Material produziert – die Studierenden haben selbst Videos erstellt und auf Switch Tube hochgeladen, in denen sie sich z.B. mit bestimmten Datenbanken beschäftigen oder digitale Editionen kritisch besprechen. Dieses riesige Potpourri an digitalem Datenmaterial muss ich jetzt einfach integrieren.
Die Dozierenden brauchen wahrscheinlich auch noch Vorbilder, Modelle, Ideen für den Unterricht…
Richtig, es braucht Hilfestellung und Support; auch auf Dozierendenseite muss die Hemmschwelle überwunden werden. Wenn es ein fakultatives Angebot bleibt, digital zu lehren (als z.B. Blended Learning oder Online-Kurs), dann, so mutmasse ich, entscheiden sich viele dagegen.
Es hat ja vielleicht damit zu tun, dass solche Hilfestellung institutionell verankert sein müsste, nicht nur didaktisch, aber auch Arbeitskraft für die technische Umsetzung – weil die einfach immer viel Zeit braucht…
Genau, und als Ergänzung dazu noch der Hinweis: Die Studierenden empfanden es als sehr problematisch, dass in jedem Kurs mit unterschiedlichen Konferenztools gearbeitet wurde. Da es schnell gehen musste, hat jeder das genutzt, was schon bekannt oder vorhanden war. Auch die Materialien waren sehr verstreut – OLAT, E-Mail, MS Teams… es ist herausfordernd für die Studierenden (aber auch uns Dozierenden), das zu kanalisieren und den Überblick zu behalten – sie haben ja nicht nur einen Kurs. Ich kenne aus einem anderen Kontext z.B. das open source Tool Big Blue Button, das sich gerade auch für Gruppenarbeiten sehr eignet, weil es eine Konferenzsoftware mit einem LMS verbindet.
Ein Beitrag unserer Reihe zu «Digital Humanities an der Philosophischen Fakultät». In einem schriftlichen Interview mit Barbara Flückiger hören wir von den Möglichkeiten von Deep Learning in der Filmanalyse – und noch vieles mehr. In der Reihe geben Lehrende und Forschende der PhF einen Einblick in Forschungsprojekte und Methoden «ihrer» Digital Humanities und zeigen uns, welche Technologien in ihrer Disziplin zum Einsatz kommen.
Frau Flückiger, bitte stellen Sie sich vor!
Mein Name ist Barbara Flückiger und ich bin Professorin für Filmwissenschaft. Vor meiner akademischen Karriere war ich international in der Filmproduktion tätig. Diesen beruflichen Hintergrund in Engineering und in der Filmpraxis bringe ich nun konsequent in meine filmwissenschaftliche Forschung und Lehre ein, in der ich mich schwerpunktmässig mit technologischer Innovation und ihren Konsequenzen für die Filmästhetik auseinandersetze. 2015 habe ich mit einem interdisziplinären Projekt einen Advanced Grant des European Research Council zur Untersuchung von historischen Filmfarben eingeworben. Ein komplementäres SNF-Projekt setzt sich mit kulturellen Faktoren der Technikgeschichte auseinander. Ausserdem nehmen wir physikalische und chemische Untersuchungen von Filmmaterialien vor.
Abb. 1 Multi-spektrale Scanner-Einheit für historische Farbfilme, entwickelt im ERC Proof-of-Concept VeCoScan, siehe Video https://vimeo.com/417111087
Obwohl meine Forschung grundlegende Fragen behandelt, sind die Ergebnisse auch für die Anwendung relevant. So entwickle ich mit meinem interdisziplinären Team wissenschaftlich fundierte Methoden für die Digitalisierung des Filmerbes, die sich in technisch avancierten Workflows umsetzen lassen. 2018 habe ich dafür einen Proof-of-Concept des European Research Council erhalten, um die wissenschaftlichen Erkenntnisse auf ihre praktische Umsetzung hin zu untersuchen. Und schliesslich präsentierten wir unsere Forschung mit einer Förderung durch SNF-Agora im letzten Herbst in einer Ausstellung im Fotomuseum Winterthur sowie mit verschiedenen Filmprogrammen einer breiteren Öffentlichkeit.
Abb. 2 Ausstellung Color Mania im Fotomuseum Winterthur
Was verstehen Sie unter «Digital Humanities»?
Ganz allgemein sind Digital Humanities Verfahren und Werkzeuge, die sich digitaler Methoden zur Bearbeitung geisteswissenschaftlicher Fragestellungen bedienen. Sie haben ihre Grundlagen in computergestützten Analysen, die zunächst in den Sprachwissenschaften für Korpusanalysen Verwendung fanden. Heute sind die Sprachwissenschaften nach wie vor sehr dominant. Ein weiteres relativ gut etabliertes Feld sind digitale Methoden in der Bildwissenschaft. Hingegen ist die Analyse von audio-visuellen Bewegtbildern – also Film und Video – noch wenig verbreitet, obwohl es seit rund 20 Jahren immer wieder Ansätze in diesem Bereich gegeben hat. Wegen des hohen Datenumfangs und des komplexen Zusammenspiels von Bild, Bewegung und Ton sind die Anforderungen in diesem Bereich sehr viel höher, sowohl was die Datenverarbeitung betrifft als auch hinsichtlich der Analyse-Instrumente. In den Digital Humanities kommen sowohl qualitative als auch quantitative Methoden zum Einsatz. Zunehmend basieren diese Werkzeuge auf Deep Learning mit neuronalen Netzen.
Abb. 3 Deep Learning Tool zur Gender-Erkennung in Farbfilmen, hier Une femme est une femme (FRA 1961, Jean-Luc Godard), entwickelt im Rahmen von ERC Advanced Grant FilmColors von Marius Högger and Mirko Serbak, Institut für Informatik, Universität Zürich
Könnten Sie uns eines Ihrer Forschungsprojekte im Bereich Digital Humanities vorstellen?
Derzeit untersuchen wir die Technologie und Ästhetik von historischen Filmfarben sowie die kulturelle Kontextualisierung dieser Entwicklungen mit einem interdisziplinären Ansatz. Im ERC Advanced Grant FilmColors haben wir ein Korpus von mehr als 400 Filmen von 1895 bis rund 1995 mit Ansätzen der Digital Humanities untersucht. In einem weiteren SNF-Projekt kommen nun Animationsfilme und neuere digitale Produktionen dazu, für die wir diese Methoden weiterentwickeln.
Abb. 4 Historische Filmfarben aus den ersten drei Dekaden der Filmgeschichte. Mehr als 200 historische Farbfilmverfahren sind systematisiert präsentiert auf der Online-Plattform Timeline of Historical Film Colors, illustriert mit mehr als 20’000 Fotografien von historischen Farbfilmen aus Archiven in Europa, den USA und Japan.
Was sind die spezifischen Methoden «der Digital Humanities», die Sie in diesem Projekt anwenden?
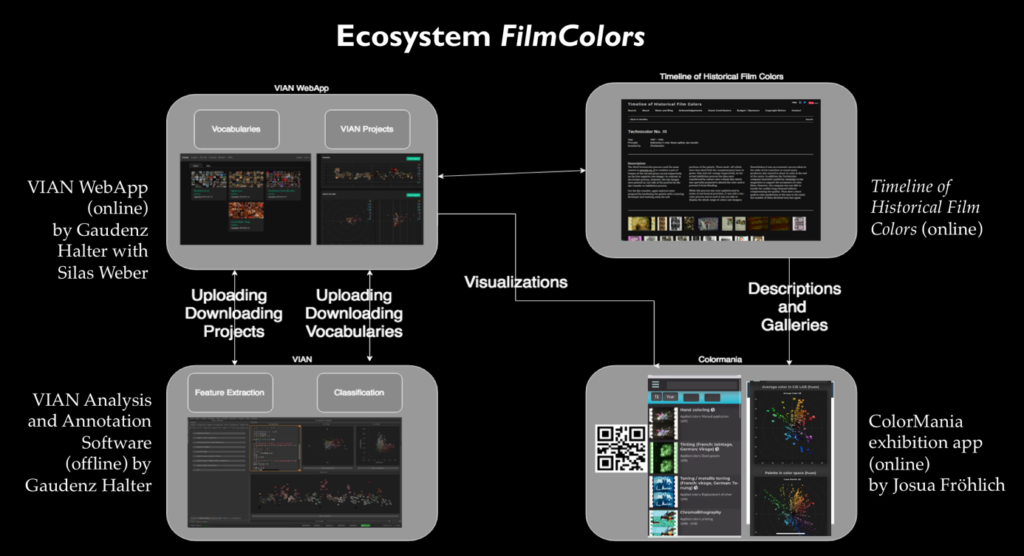
Das Fundament für die derzeitigen Projekte legte die Online-Plattform Timeline of Historical Film Colorszu historischen Farbfilmprozessen. Ab 2012 habe ich sie als umfassende interaktive Ressource für alle Aspekte der technischen Grundlagen, ästhetischen Erscheinungsbilder, Identifikation, Vermessung, Restaurierung und ästhetische Analyse aufgebaut, zunächst mit einer Crowd-Funding-Kampagne und eigenen finanziellen Mitteln. Sie umfasst heute mehrere Hundert Einzeleinträge zu den mannigfaltigen Farbfilmverfahren. Inzwischen haben mein Team und ich mit einem eigens dafür entwickelten Kamera-Set-up mehr als 20’000 Fotos von historischen Farbfilmen in Filmarchiven in Europa, den USA und Japan aufgenommen, die wir online in Galerien präsentieren. Diese Plattform ist Teil eines sich weiter ausdehnenden digitalen Ökosystems.
Abb. 5 Das digitale Ökosystem mit dem Offline-Analyse-Tool VIAN, der Online-Plattform VIAN WebApp zur Auswertung und Visualisierung auf Korpusebene, der Timeline of Historical Film Colors und der ColorMania-App für die Ausstellung im Fotomuseum Winterthur.
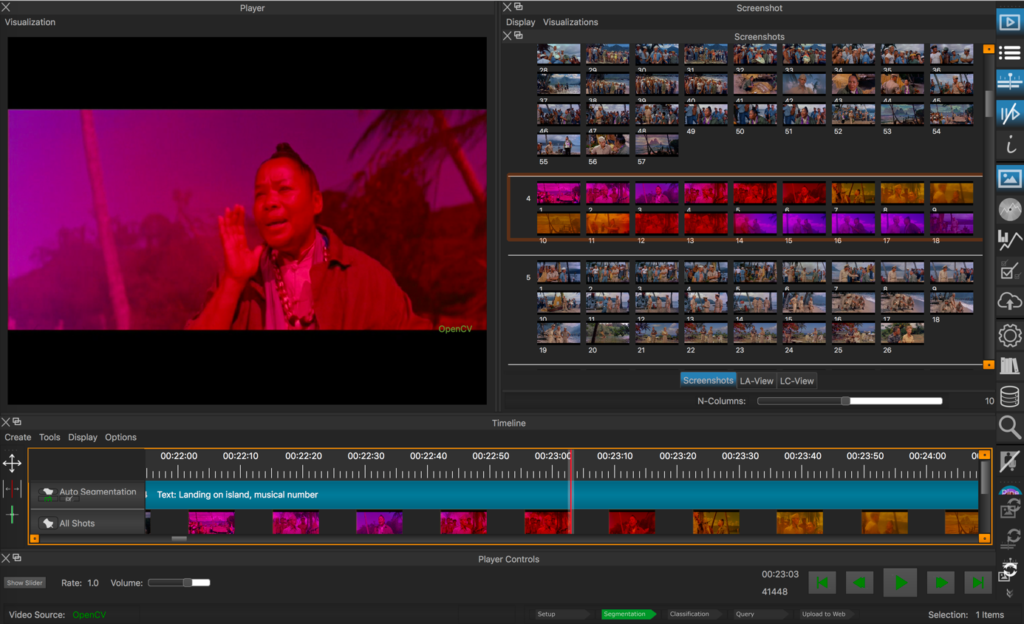
Im ERC Advanced Grant FilmColors entwickeln wir seit 2017 in Zusammenarbeit mit dem Visualization and MultiMedia Lab von Renato Pajarola (IFI UZH) nun das Digital-Humanities-Tool VIAN für die Film-Annotation und -Analyse auch mit Unterstützung durch Digitale Lehre und Forschung, der Digital Society Initiative und Citizen Science. Entwickler ist Gaudenz Halter, der ein fantastisches Werkzeug mit vielen auf die Bedürfnisse der filmästhetischen Forschung zugeschnittenen Features geschaffen hat.
Abb. 6 Analyse- und Annotationssystem VIAN, Interface mit Segmentierungsleiste und Screenshot-Manager. Film: South Pacific (USA 1958, Joshua Logan)
Dieses in Python programmierte Offline-Tool ist mit der Crowdsourcing-Plattform VIAN WebApp verknüpft, die ebenfalls hauptsächlich Gaudenz Halter entwickelt. Dort sind alle Filmanalysen des Korpus für die Auswertung und Visualisierung der Ergebnisse online verfügbar.
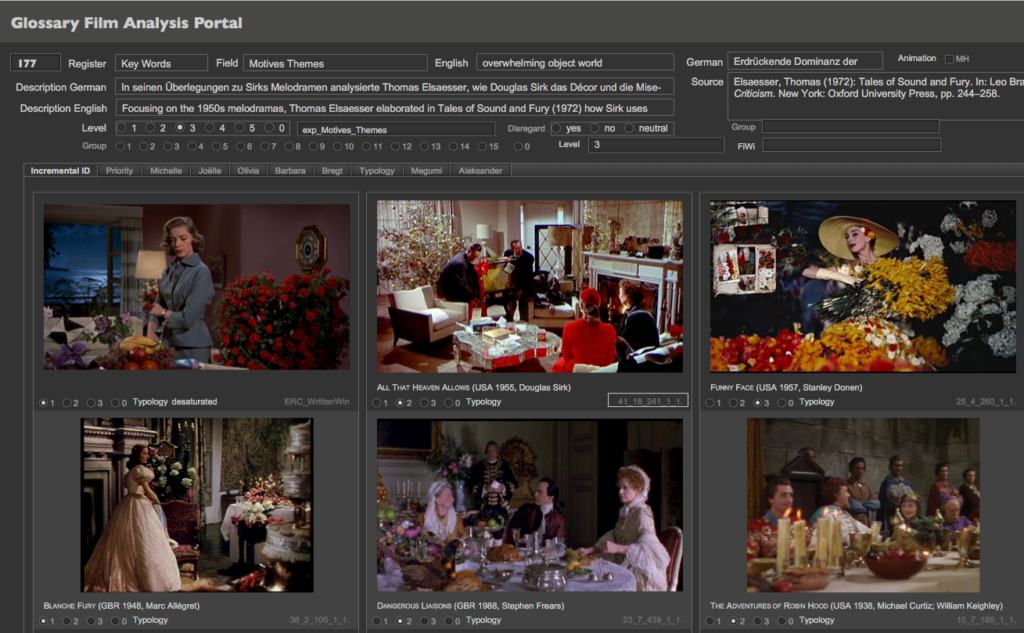
Abb. 7 Kolorimetrische Analyse und Extraktion von Farbpaletten in VIAN. Film: Sedmikrásky [Daisies] (CZE 1966, Vera Chytilová), siehe Tutorial zur Kolorimetrie https://vimeo.com/378587418In VIAN kommen zusätzlich zu manuellen Methoden Deep Learning Tools zum Einsatz, welche unter anderem eine Figur/Grund-Trennung vornimmt oder Figuren und Gender automatisch erkennen kann. Nach und nach implementieren wir zudem automatische Analyse von Bildkompositionen, visueller Komplexität, Farbverteilungen, Mustern und Texturen. Die Filme werden automatisch segmentiert, Screenshots erstellt und gemanagt. Zur Auswertung gehört die Figur-/Grund-Trennung, die kolorimetrische Analyse und viele Visualisierungsmethoden. Diese Features sind in auch in die WebApp integriert, was es ermöglicht, das ganze Korpus oder bestimmte Subkorpora, aber auch einzelne Filme oder Segmente auszuwerten und zu visualisieren. Zu diesem Zweck haben wir im Projekt ERC Advanced Grant FilmColors ein kontrolliertes Vokabular von rund 1’200 analytischen und theoretischen Konzepten definiert. Jedes dieser Konzepte ist in einem Glossar mit exemplarischen Filmbildern dargestellt mit Auswertungen zur Häufigkeit in bestimmten Perioden, Farbprozessen oder Filmgenres.
Abb. 8 Definition und Illustration eines der theoretischen und analytischen Konzepte, die «erdrückende Dominanz der Objektwelt» in der FileMaker-Glossardatenbank. Dieses kontrollierte Vokabular ist nun in VIAN und in die VIAN WebApp integriert.
Für die manuelle Annotation haben wir zunächst ein Netzwerk von relationalen Datenbanken in FileMaker erstellt, das ich weitgehend selbst programmierte. So konnte ich sehr flexibel auf Desiderate aus dem Team reagieren. Aus diesen Analysen sind mehr als 170’000 Screenshots und mehr als eine halbe Million Aufsummierungen von Resultaten entstanden. Anschliessend hat Gaudenz Halter alle Resultate in die VIAN WebApp integriert; sowohl als von Menschen lesbare JSON-Dateien wie auch als numerische Werte in HDF5-Daten-Containern.
Abb. 9 Interaktive Visualisierung von Resultaten auf Korpus-Ebene in der VIAN WebApp, hier Abfrage monochrome Filter in Filmen von 1955–1995, siehe Video https://vimeo.com/402360042
Welchen Mehrwert bringen Ihnen diese Methoden in diesen Projekten, verglichen mit «analogen» Ansätzen?
Der Mehrwert ist enorm. Ohne solche Ansätze wäre die kollaborative Arbeit an so grossen Korpora gar nicht möglich. Um solche Tools zu entwickeln, ist jedoch eine vertiefte interdisziplinäre Zusammenarbeit zwischen den Geisteswissenschaften und der Informatik notwendig, denn alle Konzepte, alle Auswertungs- und Analysemethoden, alle Ansätze zur Visualisierung der Analysen müssen aus beiden Disziplinen theoretisiert und reflektiert werden.
Wenn diese Voraussetzungen gegeben sind, lassen sich über Visualisierungen als diagrammatische Methoden neue Einsichten gewinnen, die den sprachlichen Horizont überschreiten und unmittelbar der Anschauung zugänglich sind. Dies ist für das audio-visuelle Medium Film, aber auch für andere visuelle Gegenstandsbereiche von unschätzbarem Wert; ohne solche Methoden der systematischen Untersuchung bleiben Ergebnisse anekdotisch und abstrakt zugleich. Visualisierungen schaffen also neue Formen von Evidenz.
Allerdings fallen einem die Ergebnisse auch mit solchen hochausdifferenzierten Werkzeugen nicht in den Schoss. Sie bedürfen immer der Reflexion, der Kontextualisierung und der Interpretation. Oftmals sind die Ergebnisse weit weniger eindeutig, als man das gerne hätte, und weder eine reine Auswertung noch eine Visualisierung ist bereits ein Ergebnis, sondern die Resultate bedürfen immer der Interpretation. Als Forschende müssen wir daher Hypothesen bilden und mit neuen Abfragen oder Visualisierungen differenziertere Resultate erzeugen.
Deshalb ist es von entscheidendem Wert, dass wir mit VIAN Ergebnisse und Abfragen interaktiv, basierend auf dem individuellen Forschungsinteresse anpassen können. So erhalten wir nicht nur Übersichtsvisualisierungen, sondern wir können von der Korpusebene in die einzelnen Szenen und Bilder hineinzoomen und sie uns anzeigen lassen, um detailliertere Informationen zu bekommen.
Wären diese Ansätze auch für andere Disziplinen anwendbar?
Ja, wir arbeiten nun mit anderen Fachbereichen aus den Geisteswissenschaften zusammen, unter anderem mit der Kunstgeschichte SARI / Digital Visual Studies von Prof. Dr. Tristan Weddigen und mit der Sprachwissenschaft in LiRI von Prof. Dr. Elisabeth Stark. Diese Tools lassen sich grundsätzlich in allen Disziplinen anwenden, die mit Videos oder grossen Bildersammlungen / Visualisierungen arbeiten, so in der Psychologie / Verhaltensforschung, Ethnologie, Soziologie, Politologie, aber auch in naturwissenschaftlichen Fächern wie der Medizin und den Life Sciences, zum Beispiel der Neurowissenschaft. Es sind derzeit sehr viele solche Kooperationsprojekte national und international in der Pipeline. Da habe ich dieses Jahr eine Menge Arbeit vor mir.
Wie und wo bringen Sie diese Methoden in der Lehre ein?
Wir haben seit letztem Jahr zunehmend externe Nutzer als Betatester integriert. Dies sind Doktorand*innen, PostDocs, aber auch Professor*innen der UZH und ausländischer Universitäten. Die Herausforderung besteht im Support, denn wir müssen einerseits die Usability mit den Betatestern überprüfen, andererseits die Software fortlaufend anpassen. Dafür hat uns DLF eine 20%-Stelle finanziert. Es gibt eine umfassende Dokumentation und wir erstellen Video-Tutorials für die Einführung.
Ich habe soeben einen kompetitiven Lehrkredit beantragt, damit wir VIAN im kommenden Jahr auf Bachelor- und Masterstufe in der Lehre einsetzen können. Denn auch die Dozierenden müssen geschult werden und brauchen Unterstützung. Es ist ein Irrglaube, eine solch differenzierte Software sei selbsterklärend. Obwohl VIAN sehr flexibel und intuitiv ist, muss man den Umgang damit doch lernen, und es braucht etwas Übung, bis man effizient damit arbeiten kann.
Die Studierenden erhalten so Gelegenheit, sich mit digitalen Werkzeugen und Methoden auseinanderzusetzen, neue Kompetenzen in der Anwendung zu erwerben und gleichzeitig aktiv an der Weiterentwicklung mitzuarbeiten, indem sie Feedback geben und ihre Bedürfnisse artikulieren.
Welche technischen Kenntnisse sollten Studierende mitbringen?
Das Interface von VIAN verlangt keine besonderen technischen Kenntnisse, denn es ist spezifisch auf den Einsatz durch Geisteswissenschaftler und für die ästhetische bzw. narratologische Analyse entwickelt worden. Allerdings ist es von Vorteil, wenn man technikaffin ist und gerne am Computer arbeitet. Auch eine Vorstellung von Auswertungen und der Arbeit mit Datenbanken ist von Vorteil, lässt sich aber ohne spezifische Grundkenntnisse im Lauf der Anwendung erwerben.
An der Timeline of Historical Film Colors arbeiten Studierende im Datenmanagement mit und kodieren die Quellen in HTML, die sie danach in das Backend der Plattform einpflegen und mit einem Thesaurus annotieren.
Wo sehen Sie Bedarf an Infrastruktur, Informatik-Grundausbildung oder anderem an der Philosophischen Fakultät, um «Digital Humanities» in Ihrem Fachgebiet betreiben und in der Lehre einbringen zu können?
Die Philosophische Fakultät braucht dringend eine Digital-Humanities-Strategie, sie muss verstehen, dass sie es sich nicht leisten kann, auf diese digitalen Ansätze und Methoden in den Geisteswissenschaften zu verzichten. Diese Strategie muss von der Unileitung gestützt und eingefordert werden, denn die Universität Zürich muss sich im internationalen Feld positionieren. International findet zunehmend ein Wettbewerb um die besten Talente statt; die besten Universitäten der Welt bemühen sich sowohl um die begabtesten Studierenden als auch um herausragende Forschende. Mit der Digital Society Initiative haben wir bereits einen Verbund von exzellenten Professor*innen auf Universitätsebene, in dem ich seit der Gründung dabei bin.
Mit meinem Projekt, SARI / Digital Visual Studies sowie LiRI sind wir in einer guten Ausgangsposition, aber diese Einzelinitiativen müssen in einen übergeordneten institutionellen Rahmen eingebettet werden und vor allem müssen für diese Integration finanzielle Mittel gesprochen werden. Digitale Ansätze sind nicht selbsterhaltend, sie sind einem steten Wandel unterworfen und entwickeln sich dynamisch im Verbund mit Hardware und Trends in anderen Anwendungsbereichen. Um den Erhalt zu garantieren, brauchen wir spezialisierte technische Infrastruktur, wir brauchen Entwickler, die unsere Methoden und Werkzeuge verstehen und umsetzen, wir brauchen interdisziplinär denkende Doktorand*innen und PostDocs, wir brauchen Techniker*innen, die sich mit den Anforderungen der Forschung beschäftigen. Anders als in den Naturwissenschaften, in denen es selbstverständlich ist, dass ein Labor Mittel hat, um die technische Infrastruktur à jour zu halten, sind diese Anforderungen in den Geisteswissenschaften noch wenig präsent. Bei uns ist die Förderung in der Regel projektbasiert. In meinem Fall sind die Mittel aus dem ERC Advanced Grant mittlerweile erschöpft; das bedeutet, dass die Weiterentwicklung des gesamten Ökoystems, das wir um VIAN herum aufgebaut haben, akut gefährdet ist. Dies, obwohl das Interesse an den Werkzeugen – sowohl uniintern als auch international, fachbezogen und fachübergreifend – sehr gross ist. Der Ball liegt nun bei der Universität, die Grundsicherung und langfristige Perspektive für solche Methoden und Tools sicherzustellen. Dafür ist eine strukturierte Kommunikation aller Stufen und Einheiten der Universität notwendig sowie auch die Kommunikation nach aussen, denn dieses Feld ist sehr attraktiv.
Dank meiner Vorarbeiten kommen viele potenzielle nationale und internationale Partner aktiv auf mich zu. Sie wollen sich vernetzen und von den Entwicklungen profitieren. Das begrüsse ich sehr und pflege einen kooperativen und offenen Austausch. Mit dem Joint Digital Humanities Fund haben wir bereits eine etablierte Kooperation mit der FU Berlin sowie neu der Hebrew University in Jerusalem. Wir arbeiten mit einem internationalen Konsortium an Standardisierungen, welche die Interoperabilität der Ansätze und Tools sicherstellen soll und planen ein übergeordnetes Ökosystem, in das diese Werkzeuge integriert werden können.
Das vergangene Semester hat gezeigt, dass die digitale Lehre und Forschung ein unverzichtbarer Baustein für die Weiterentwicklung der Universitäten sind. Die UZH darf den Anschluss nicht verpassen.
Gibt es Fragen, die ich nicht gestellt habe, die für die Diskussion aber wichtig sind?
Ja, meine persönlichen Ressourcen. Ich habe eine Professur ad personam, ohne Stellen. Meine Arbeitsbelastung in den vergangenen Jahren war gigantisch, und es sieht nicht nach Besserung aus. Auch wenn ich über sehr viel Energie verfüge und überraschend zäh bin, muss ich zu viel leisten. Auf Dauer ist das nicht machbar.
Aber ich bin auch eine ziemlich unerschütterliche Optimistin und nehme an, dass sich die Dinge am Ende schon zum Positiven entfalten.
Dieser Beitrag entstand im Rahmen einer kleinen Reihe zu «Digital Humanities an der Philosophischen Fakultät». Lehrende und Forschende der PhF geben uns einen Einblick in Forschungsprojekte und Methoden «ihrer» Digital Humanities und zeigen uns, welche Technologien in ihrer Disziplin zum Einsatz kommen. Wir diskutieren den Begriff «Digital Humanities» von ganz verschiedenen Perspektiven aus. Heute stellt uns Noah Bubenhofer, Professor am Deutschen Seminar, eine digitale Korpuslinguistik vor.
Herr Bubenhofer, vielen Dank, dass Sie bei dieser Reihe mitmachen – bitte stellen Sie sich kurz vor!
Ich bin germanistischer Linguist, seit September 2019 Professor am Deutschen Seminar der UZH. Ich interessiere mich für eine kultur- und sozialwissenschaftlich orientierte Linguistik, die davon ausgeht, dass Sprache und gesellschaftliches Handeln in einem engen Verhältnis stehen und dass man deshalb über linguistische Analysen etwas darüber lernen kann, wie eine Gesellschaft oder eine Kultur funktioniert.
Ich arbeite sehr stark korpuslinguistisch – ein Korpus ist letztlich eine Sammlung von Textdaten, die meist linguistisch aufbereitet sind und linguistisch analysiert werden. In der Korpuslinguistik verbinde ich quantitative mit qualitativen Methoden, um grössere Textdatenmengen auf Musterhaftigkeit hin analysieren zu können – hier verwende ich natürlich digitale Methoden. Korpuslinguistik gibt es schon sehr lange; mit der Digitalisierung hat sie einen neuen Drive erhalten, weil es sehr viel einfacher geworden ist, sehr grosse Textdatenmengen zu verarbeiten.
Was verstehen Sie unter «Digital Humanities», auch in Bezug zu Ihrem Forschungsgebiet?
Ich erlebe «Digital Humanities» als extrem heterogen, und manchmal ist es gar nicht so klar, ob ich das, was ich mache, auch dazu zählen kann – gerade weil die Korpuslinguistik eigentlich schon eine sehr lange Tradition in der Linguistik hat.
Einerseits bedeutet «Digital Humanities» für mich, digitale Methoden auf digitalen Daten anzuwenden und letztlich geisteswissenschaftliche Fragestellungen zu verfolgen. Andererseits reflektiert man «Digitalität per se» mit geisteswissenschaftlichen Theorien: Was macht «Verdatung» mit Informationen, was ist eigentlich ein Algorithmus, und so weiter.
Die Kombination dieser beider Aspekte macht das Alleinstellungsmerkmal von «Digital Humanities» im Vergleich zu anderen Disziplinen aus, die auch mit digitalen Daten und Methoden arbeiten, wie z.B. Informatik, Data Mining o.ä.
Sie sagten «Disziplin» im Zusammenhang mit Digital Humanities …
[lacht] Dieselbe Debatte gibt es auch in der Korpuslinguistik – ist sie eine Subdisziplin der Linguistik oder ist sie eher ein Denkstil? Ich argumentiere immer für Letzteres, da es eine bestimmte Art und Weise ist, Sprache anzusehen.
Ferdinand de Saussure führte die Unterscheidung von «langue» und «parole» ein, dabei ist «langue» sozusagen das Sprachsystem und «parole» die tatsächlich geäusserte Sprache. Lange interessierte sich die Linguistik hauptsächlich für die «langue». Die Korpuslinguistik machte erst den Fokus auf die «parole» stark, indem die Musterhaftigkeit in der gesprochenen und geschriebenen Sprache untersucht wurde.
Diese Verschiebung der Perspektive findet man in den Digital Humanities teilweise wieder. Man ist an anderen Aspekten der Daten interessiert und hat dadurch auch ein anderes theoretisches Modell im Hintergrund. Deshalb sind die Digital Humanities für mich auch eine Denkrichtung, die versucht, mit spezifischen Methoden einen neuen Blick auf die vorhandenen Daten zu erhalten.
Können Sie uns ein Beispiel geben, vielleicht an einem Ihrer Forschungsprojekte?
In einem Projekt habe ich Alltagserzählungen, genauer Geburtsberichte gesammelt. In diesen schrieben Mütter nieder, wie sie die Geburt ihres Kindes erlebt hatten. Die Berichte stammen aus Threads in Online-Foren, die genau für dieses Genre vorgesehen sind. Ich habe nun 14’000 Berichte aus sechs unterschiedlichen deutschsprachigen Foren gesammelt, analysiert und dabei eine Diskrepanz zwischen diesem sehr individuellen Erlebnis und der Erzählung darüber aufgezeigt: In der Erzählung konnte eine extreme Musterhaftigkeit mit einem bestimmten erzähltypischen Ablauf festgestellt werden, mit bestimmten Themen und Motiven, die sich wiederholten. Die Musterhaftigkeit dieser Erzählungen konnte mit Hilfe digitaler Methoden freigelegt werden.
Genau hier kommt auch wieder der Unterschied z.B. zu reinem Data Mining ins Spiel, wo Fragen wie Narrativität und Sequenzialität zu kurz kommen. In den Geisteswissenschaften ist es uns dagegen klar, dass diese Aspekte eine Rolle spielen: Man kann einen Text nicht einfach als «Sack von Wörtern» (bag of words) auffassen, sondern es spielt eine Rolle, in welcher Sequenz diese Wörter vorkommen.
Es ging in diesem Projekt also auch darum, die Methodik so anzupassen, dass man diese narrativen Strukturen identifizieren kann.
Wie gehen Sie (technisch) vor, um eine solche Analyse durchzuführen?
Zunächst müssen die Daten «gecrawlt», d.h. automatisiert vom Web heruntergeladen werden. In einem aktuellen Projekt zu COVID19 News-Kommentaren haben wir z.B. mit Python und Selenium gearbeitet. Dabei übernimmt Selenium die «Benutzerinteraktion» auf einer dynamischen Webseite – diese sind heute ja nicht mehr einfach statisches HTML.
Diese Daten werden nun linguistisch, d.h. mit Wortarten-Tagging, syntaktischem Parsing, semantischen Annotationen etc. versehen. Dafür verwenden wir an unserem Lehrstuhl das UIMA-Framework, das mit Modulen oder eigenen Python-Skripts erweitert werden kann, die das Tagging oder andere Verarbeitungsschritte auf diesen Textdaten durchführen.
Im nächsten Schritt gehen diese verarbeiteten Daten in die Corpus Workbench, eine Datenbank, die spezialisiert ist, korpuslinguistisch annotierte Daten zu verwalten und zu analysieren. Für die Analyse wichtig sind in unserem Gebiet die n-Gramme – Gruppen von n Wörtern, sprachliche Muster –, die wir mit unserer selbst entwickelten Software cwb-n-grams berechnen können. Wie diese n-Gramme berechnet werden, kann dabei ganz unterschiedlich sein: Nimmt man als Basis die Grundformen der Wörter, reduziert man Redundanzen, behält man «Füllwörter» oder nicht, wie lange soll das n-Gramm sein, etc. Wir haben die Methodik zudem so erweitert, dass wir zusätzlich auch die erstellten Annotationen mit einbeziehen.
Die (statistische) Analyse selber kann man schliesslich z.B. mit R und plotly durchführen, für das ein Paket existiert, das direkt auf die Corpus Workbench zugreifen kann. Hier vergleichen wir die Häufigkeiten jeweils mit einem Referenzkorpus, um statistisch signifikante n-Gramme finden zu können. Signifikant heisst in dem Zusammenhang: Welche n-Gramme sind typisch für Geburtsberichte und nicht aus anderen Gründen häufig vorgekommen.
Der Output kann z.B. eine interaktive Grafik sein – hier das Beispiel zum Projekt «Geburtsgeschichten», das typische Positionen der n-Gramme im Verlauf der Erzählung darstellt. Man sieht an den n-Grammen, dass diese sprachlichen Muster über die 14’000 Texte hinweg immer wieder gleich und an ähnlichen Positionen in der Erzählung vorkommen. Die y-Achse zeigt die Standardabweichung bezüglich Position in der Geschichte: Je weiter oben ein n-Gramm erscheint, desto variabler war die Position im Verlauf. Auf der Grafik sind bestimmte Cluster von n-Grammen sichtbar, die aber weniger variabel waren, gegen Ende der Erzählung z.B. das n-Gramm «gleich auf den Bauch gelegt».
Eine rhetorische Frage: Was ist der Mehrwert gegenüber analogen Methoden?
[lacht] … Genau, was bringt’s wirklich? Zum einen, 14’000 Geschichten kann ich nicht einfach durchlesen. Aber im Ernst: Es zeigt sich eine Musterhaftigkeit in der Sprache, die nicht auffallen kann, wenn man nur Einzeltexte vor sich hat. Ich finde dieses datengeleitete Paradigma wichtig: Welche Strukturen ergeben sich eigentlich datengeleitet und nicht theoriegeleitet? Sehr wichtig ist dabei, dass wir im Anschluss eine geisteswissenschaftliche Interpretation davon machen. Man hat nicht zuerst eine theoriegeleitete Hypothese, die man stützen oder verwerfen kann, sondern generiert die Hypothese vielleicht erst durch diese Interpretation. Natürlich muss man dann wieder zurück in die Daten und prüfen, ob diese Hypothese wirklich stimmt – und man darf nicht vergessen, dass man trotz des induktiven Vorgehens noch Prämissen gesetzt hat: Allein die Definition, was als Wort aufgefasst wird, welche Daten wähle ich aus, etc.
Eine Challenge in der Linguistik ist heute, dass die Informatik uns neuronale Lernmethoden gibt, die statistische Modelle aus den praktisch unverarbeiteten Daten lernen. Der Algorithmus muss gar nicht mehr wissen, was ein Wort oder eine Wortart ist. Die Idee ist dann, dass sich die Musterhaftigkeit und allenfalls Kategorien wie Wortarten aus den Daten ergeben. Dies stellt natürlich die klassische Linguistik in Frage – wir experimentieren aber damit und fragen uns, inwiefern linguistische Theorien helfen zu verstehen, warum solche Methoden überhaupt funktionieren und wie sie verbessert werden können. Und doch ist es auch hier wichtig zu sehen, dass neuronale Lernmethoden keinesfalls objektive, neutrale Modellierungen von Sprache darstellen, sondern mit der Datenauswahl und den gewählten Parametern eben spezifischen Sprachgebrauch abbilden. Die Modelle sind genauso voller Verzerrungen – wir würden sagen: diskursiv geprägt – wie ihre Datengrundlage, was z.B. bei AI-Anwendungen problematische Folgen haben kann.
Für die Bearbeitung dieser Fragestellungen werden sehr viele verschiedene Technologiekenntnisse, aber auch sehr viel theoretisches Wissen vorausgesetzt – wie kann man die Studierenden da heranführen?
Man kann heute nicht Linguistik studieren, ohne eine Vorstellung zu haben, was algorithmisch möglich ist. Sie müssen verstehen, was ein Skript machen kann, wie HTML, XML und Datenbanken funktionieren, oder auch, was Machine Learning ist.
Als ich noch in Dresden war, haben wir eine Einführung in die Programmierung für Germanistinnen und Germanisten gegeben, die sich sehr bewährt hat. Der Kurs war sehr niederschwellig, die Studierenden sollten ein kleines Skript zu einem linguistischen Projekt schreiben. Einige Studierende vertiefen diese Kenntnisse weiter, andere nicht – doch zumindest können sie auf Augenhöhe mit Personen sprechen, die sie vielleicht in weiteren Projekten unterstützen.
Hier an der UZH plane ich gerade, hoffentlich mit einem Lehrkredit, ein E-Learning Modul zu Programmierkompetenzen für Geisteswissenschaftlerinnen und Geisteswissenschaftler. Das Modul soll aus Bausteinen bestehen, die man auch gut in andere, bereits bestehende Module einbinden kann und die teilweise auch curricular verpflichtend sind.
Heisst das, dass die Programmierkenntnisse disziplinär gebunden unterrichtet werden sollen? Oder lernt man besser Python in einem Pythonkurs, SQL in einem SQL-Kurs etc.?
Es gibt natürlich unterschiedliche Lerntypen, doch m.E. ist eine disziplinäre Verortung für die Mehrheit der Studierenden in den Geisteswissenschaften wichtig, weil man an den geisteswissenschaftlichen Fragen interessiert ist. Sonst hätte man vielleicht Informatik studiert. Es ist viel einfacher, wenn man eine konkrete Forschungsfrage hat, der man nachgehen kann und entlang derer man die nötigen Kenntnisse erwirbt. Man ist so einfach viel motivierter.
Hier schliesst sich auch der Bogen zur Frage, was «Digital Humanities» sein könnten…
Ja, denn für uns Geisteswissenschaftlerinnen und Geisteswissenschaftler ist eine Methode dann interessant, wenn sie «nahrhaft» für Interpretation ist, d.h. wenn ich daraus etwas machen kann, das mir in meinen Fragen weiterhilft. Es ist eine andere Art von Nützlichkeit als eine rein technologische für eine Anwendung, aber natürlich benötigen wir die Hilfe von anderen Disziplinen, wir haben das Know-How nicht, z.B. einen Part-of-speech-Tagger oder statistische Methoden zu verbessern.
Haben wir ein wichtiges Thema in der Diskussion ausgelassen, haben Sie eine Ergänzung oder einen Ausblick?
In meiner Habilitationsschrift, die demnächst erscheint, geht es um die «Diagrammatik», nämlich wie Darstellungen und Visualisierungen helfen, Daten anders zu verstehen. Es geht hier nicht nur um quantitative Aspekte, sondern darum, wie verschiedene Darstellungsformen neue Sichtweisen auf Daten ermöglichen.
Ein Beispiel ist die «Konkordanzliste»: Man hat hier einen Suchausdruck und sieht dessen unmittelbaren Kontext in verschiedenen Texten. Die Konkordanzdarstellung gibt es schon seit dem Mittelalter, er bricht die Einheit des Textes auf und versucht, einen Blick auf Fundstellen listenförmig darzustellen. Dadurch wird der Text «zerstört», aber gleichzeitig gewinnt man ganz viel, weil man eine neue Sicht erhält.
Für mich ist auch das auch eine Frage für die Digital Humanities, weil wir eigentlich ständig versuchen, unsere Daten in andere Ansichten zu transformieren, um etwas Neues daraus zu gewinnen. Viele dieser Visualisierungen sind erst mit den digitalen Mitteln möglich geworden.
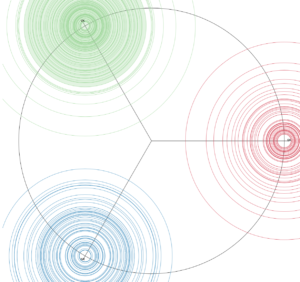
In diesem Beispiel werden Gesprächstranskripte visualisiert: Die drei Gesprächsteilnehmerinnen und Gesprächsteilnehmer sind als Kreiszentren dargestellt. Die Jahresringe stellen einzelne Beiträge der Teilnehmenden dar. Je mehr Ringe, desto mehr sogenannte “turns” wurden von dieser Person beigetragen. Die verschiedenen Durchmesser der Jahresringe ergeben sich aus den Beitragslängen. Einige Beispiele können auf Noah Bubenhofers Seite gleich ausprobiert werden.
Herr Bubenhofer, ich danke Ihnen für dieses Gespräch!


 [Tilia Ellendorff, TE]: Mein Name ist Tilia Ellendorff. Ursprünglich habe ich Grundschullehramt mit den Fächern Englisch und Deutsch studiert an der Universität Paderborn. Anschliessend habe ich mich aber entschlossen, mich auf Linguistik und Computerlinguistik zu konzentrieren – zunächst mit einem Bachelor in Linguistik, dann mit einem Internationalen Masterstudium in Computerlinguistik in Wolverhampton (GB) und Faro (P), über Erasmus Mundus. Schliesslich bin ich für das Doktorat in Computerlinguistik nach Zürich gekommen. Mein Thema war Biomedical Text Mining – in meinem Projekt ging es darum, in medizinischen Publikationen die Beziehung zwischen ätiologischen, also auslösenden, Faktoren von psychiatrischen Erkrankungen zu extrahieren. Hier besteht nämlich das Problem, dass es unmöglich ist, die gesamte Literatur auf diesem Gebiet zu lesen. Es ist schwierig, so einen Überblick über alle Faktoren zu gewinnen. Ich habe dazu ein System gebaut, das dies unterstützt und automatisch aus den Texten extrahiert.
[Tilia Ellendorff, TE]: Mein Name ist Tilia Ellendorff. Ursprünglich habe ich Grundschullehramt mit den Fächern Englisch und Deutsch studiert an der Universität Paderborn. Anschliessend habe ich mich aber entschlossen, mich auf Linguistik und Computerlinguistik zu konzentrieren – zunächst mit einem Bachelor in Linguistik, dann mit einem Internationalen Masterstudium in Computerlinguistik in Wolverhampton (GB) und Faro (P), über Erasmus Mundus. Schliesslich bin ich für das Doktorat in Computerlinguistik nach Zürich gekommen. Mein Thema war Biomedical Text Mining – in meinem Projekt ging es darum, in medizinischen Publikationen die Beziehung zwischen ätiologischen, also auslösenden, Faktoren von psychiatrischen Erkrankungen zu extrahieren. Hier besteht nämlich das Problem, dass es unmöglich ist, die gesamte Literatur auf diesem Gebiet zu lesen. Es ist schwierig, so einen Überblick über alle Faktoren zu gewinnen. Ich habe dazu ein System gebaut, das dies unterstützt und automatisch aus den Texten extrahiert. [Gerold Schneider, GS]: Ich habe Englische Literatur- und Sprachwissenschaft und Computerlinguistik an der Universität Zürich studiert. Während des Doktorats habe ich einen syntaktischen Parser für Englisch entwickelt. Es ist ein System, das eine syntaktische Analyse eines Texts liefert: Was ist das Subjekt, was das Objekt, welches die untergeordneten Sätze, etc. Mit der Anwendung dieses Tools bin ich schliesslich in das Gebiet des Text Minings gelangt. Zunächst habe ich das auch zu Fachliteratur im biomedizinischen Bereich angewendet. Die gleichen Methoden konnte ich später in weiteren Disziplinen verwenden, z.B. in Projekten mit dem Institut für Politikwissenschaft im NCCR Democracy zu Demokratieforschung, oder auch in einem Projekt zu Protestforschung. Dabei geht es ja nicht nur um eine Faktensammlung, sondern meist um Meinungen, Stimmungen oder Assoziationen, die aus den Medien extrahiert werden müssen: Gerade da braucht man statistische Methoden, mit logikbasierten stösst man nur auf Widersprüche. Somit sind auch die Methoden des maschinellen Lernens unerlässlich. Die Daten und Ergebnisse müssen zum Schluss aber auch interpretiert werden können – sonst nützt die Datensammlung nicht viel. Mein breiter Hintergrund ist hier sicher von Vorteil – ich sehe mich auch als Brückenbauer zwischen Disziplinen.
[Gerold Schneider, GS]: Ich habe Englische Literatur- und Sprachwissenschaft und Computerlinguistik an der Universität Zürich studiert. Während des Doktorats habe ich einen syntaktischen Parser für Englisch entwickelt. Es ist ein System, das eine syntaktische Analyse eines Texts liefert: Was ist das Subjekt, was das Objekt, welches die untergeordneten Sätze, etc. Mit der Anwendung dieses Tools bin ich schliesslich in das Gebiet des Text Minings gelangt. Zunächst habe ich das auch zu Fachliteratur im biomedizinischen Bereich angewendet. Die gleichen Methoden konnte ich später in weiteren Disziplinen verwenden, z.B. in Projekten mit dem Institut für Politikwissenschaft im NCCR Democracy zu Demokratieforschung, oder auch in einem Projekt zu Protestforschung. Dabei geht es ja nicht nur um eine Faktensammlung, sondern meist um Meinungen, Stimmungen oder Assoziationen, die aus den Medien extrahiert werden müssen: Gerade da braucht man statistische Methoden, mit logikbasierten stösst man nur auf Widersprüche. Somit sind auch die Methoden des maschinellen Lernens unerlässlich. Die Daten und Ergebnisse müssen zum Schluss aber auch interpretiert werden können – sonst nützt die Datensammlung nicht viel. Mein breiter Hintergrund ist hier sicher von Vorteil – ich sehe mich auch als Brückenbauer zwischen Disziplinen.