In diesem Beitrag unserer Reihe zu «Digital Humanities an der Philosophischen Fakultät» hören wir von Christine Grundig, wissenschaftlicher Mitarbeiterin am Kunsthistorischen Institut, über ihre Lehrerfahrungen beim Unterricht von digitalen Methoden. In der Reihe geben Lehrende und Forschende der PhF uns einen Einblick in Forschungsprojekte und Methoden «ihrer» Digital Humanities und zeigen uns, welche Technologien in ihrer Disziplin zum Einsatz kommen.

Wer sind Sie – bitte stellen Sie sich vor!
Mein Name ist Christine Grundig, ich habe Staatsexamen für Deutsch, Englisch und Erziehungswissenschaften für das Lehramt an Gymnasien studiert und den Magister Artium an der Universität Würzburg gemacht. Nun schliesse ich gerade meine germanistische Promotion ab. Ich arbeitete v.a. in Projekten, die sich mit digitalen Editionen beschäftigten und habe so Kompetenzen im Bereich der Digital Humanities erworben. Seit Oktober 2017 bin ich als «Digital Humanities Spezialistin» am Kunsthistorischen Institut der Universität Zürich tätig [lacht] – bitte lassen Sie mich diesen Begriff jetzt nicht definieren! Als wissenschaftliche Mitarbeiterin arbeite ich im SNF-Projekt zu Heinrich Wölfflin am Lehrstuhl von Prof. Dr. Tristan Weddigen. Als Dozentin unterrichte ich in meinem Lehrprojekt «Digitale Bildwissenschaften/Digital Visual Studies» bzw. «Digital Skills», das von swissuniversities im Rahmen des Projekts «P8-Stärkung von Digital Skills in der Lehre» 2019-2020 gefördert wird.
Könnten Sie uns diese beiden Projekte kurz vorstellen?
Gegenstand unseres Editionsprojekts ist eine kritisch-kommentierte Edition sämtlicher Publikationen Heinrich Wölfflins – er ist für Kunsthistorikerinnen und Kunsthistoriker eine der zentralen Figuren. Wir haben das grosse Glück, dass wir in der Nähe seiner Wirkungsorte tätig sind – einen Teil seines Nachlasses (Foto- und Diasammlung, Bibliothek, Möbel) hat er dem Kunsthistorischen Institut vermacht. Durch die Nähe zur Universität Basel, in der ein Grossteil des archivalischen Nachlasses liegt (Notizhefte, Manuskripte, Korrespondenz), ist es uns möglich, mit bisher unveröffentlichtem Archivmaterial zu arbeiten. Dies war anderen Editionen bisher nicht oder nicht in diesem Masse möglich.
Es entsteht eine klassische Printedition (die ersten Bände sind bereits publiziert), daneben aber auch eine digitale Edition, die sich an aktuellen Technologien und Standards der Digital Humanities orientiert. Das Material wird in der digitalen Edition im Rahmen eines eigenen Wölfflin-Portals nachhaltig erschlossen, einer Forschungsplattform, die Kontextualisierungen möglich macht und v.a. auch Schnittstellen zu anderen Projekten bietet. Dazu werden die Bände, die bereits im Print erschienen sind in XML/TEI konvertiert, um sie «für das Internet fähig zu machen». Das Versehen mit Referenz- bzw. Normdaten für Werke, Personen, Objekte, Orte, historische Termini und bibliographische Angaben ist ein zentrales Anliegen. Das Portal wird auch Bildmaterial mit hochauflösenden Scans nach IIIF-Standard zugänglich machen, zudem Archivmaterial, das zum Teil mit Tools wie Transkribus oder OCR4all erarbeitet wird.
Wir werden eine semantisch angereicherte Edition bereitstellen, die aus Linked Open Data (LOD) besteht. So können wir einen möglichst grossen Nutzen für die Forschungsgemeinschaft erzielen, weil die Daten dadurch nachhaltig sind und Interoperabilität gewährleistet ist.
Und was beinhaltet das Projekt zu «Digital Skills»?
Wir schlugen im Rahmen von «P8» eine «Einführung in digitale Methoden in der Kunstgeschichte» für Bachelor- und Masterstudierende vor. Ursprünglich war der Fokus eher auf den Bildwissenschaften, doch ich merkte in den ersten Sitzungen, dass ich «ganz vorne anfangen» und den Fokus auf «digital skills» im Allgemeinen legen muss. Es mangelt an Grundkompetenzen der Studierenden im Umgang mit digitalen Methoden.
Konkret besprechen wir im Kurs zunächst, was Digital Humanities überhaupt sind, und ganz wichtig, was die Studierenden eigentlich darunter verstehen. Ich möchte wissen, in welchen Bereichen sie schon mit Tools oder digitalen Methoden gearbeitet haben. Jede/Jeder hat z.B. Datenbanken genutzt oder in Katalogen recherchiert, aber meist wissen sie gar nicht, dass das Datenbanken sind oder was genau dahintersteckt.
Man muss auf einer ganz grundlegenden Ebene aufklären und zeigen, welche Möglichkeiten es in einer Disziplin gibt, mit digitalen Methoden zu arbeiten. Wir behandeln Datenbanken, digitale Editionen, Bilderkennung und Bildannotation, IIIF-Formate oder auch Texterkennung mit OCR.
Wichtig ist mir dabei, praxis- bzw. berufsorientiert vorzugehen, wenn wir digitale Werkzeuge ausprobieren: Die Studierenden sollen ganz konkret mit Tools wie z.B. Transkribus arbeiten, weil sie nur dann die Hemmschwelle überwinden, die Angst davor verlieren. Viele denken sich nämlich, «Ich bin keine Informatikerin, kein Informatiker, ich kann das nicht». Wenn man diese Barriere überwindet, kann es durchaus vorkommen, dass Studierende sich vielleicht sogar an eigenen kleinen (Python-)Skripts versuchen, vielleicht mit etwas Unterstützung aus der Informatik oder Computerlinguistik, aber alleine die Tatsache, dass sie sich damit auseinandersetzen – das ist ganz zentral und erfreulich für mich.
Was kann man mit Transkribus oder OCR4all denn konkret machen?
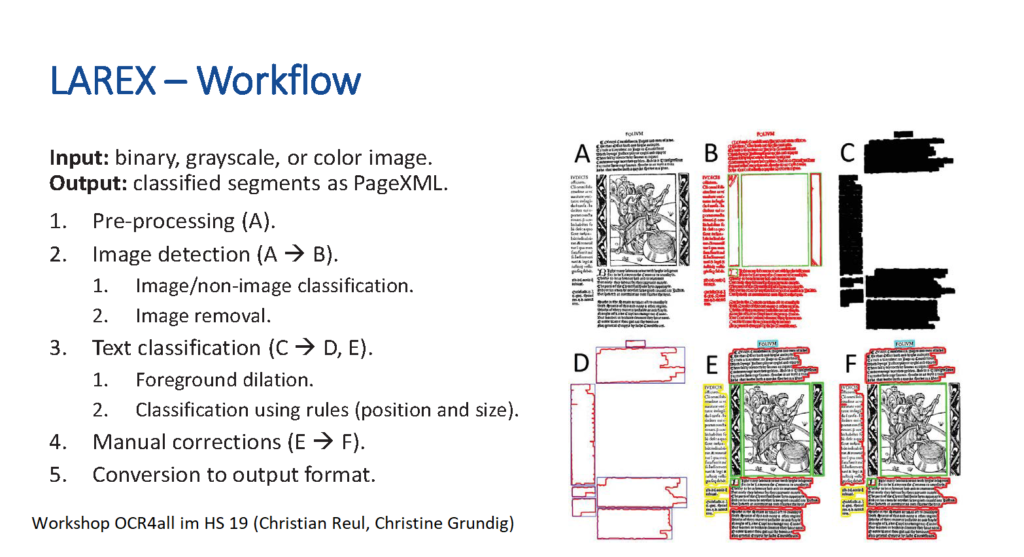
Wenn wir mit Handschriften oder historischen Drucken arbeiten, liegen uns Scans davon vor. Wir schauen dann, wie man diese digital aufbereiten kann: Zeilen segmentieren, einzelne Text- und Bildbereiche voneinander trennen usw. Dafür haben wir z.B. das Segmentierungstool Larex, das zu OCR4all gehört, und das das Layout analysiert: Dies bedeutet, Seiten zu segmentieren, die wir danach transkribieren können. Über die Textdaten, die wir durch die Transkription erhalten, lassen wir «Trainings», also Machine Learning-Algorithmen laufen. Der Output ist zunächst noch fehlerhaft; er wird von Hand korrigiert, um diese optimierten Daten wieder «durch die Maschine laufen zu lassen», sie so weiter anzulernen und dadurch das Ergebnis zu verbessern. Auf diese Weise können selbst Kurrent-Handschriften wie die von Heinrich Wölfflin automatisch erkannt werden, aber auch z.B. Drucke mit Fraktur- oder Antiqua-Schrift, für die es bereits sehr gute Modelle gibt. Diese kommen meist aus dem germanistischen Bereich, stehen aber allen zur Verfügung. So können wir interdisziplinär arbeiten, auf den Modellen aufbauen und die Daten austauschen, sie weiter trainieren.
Wenn Sie sagen, die Hemmschwelle muss überwunden werden – wie gehen Sie da im Unterricht vor, wenn Sie z.B. Daten vor sich haben?
In der Einführung haben wir uns zunächst mit Datenbanken beschäftigt, z.B. was unterscheidet eine Graphdatenbank von einer relationalen Datenbank, welche Datenmodelle stecken dahinter?
In der Hoffnung, dass das Lehrprojekt weitergeführt werden kann, möchte ich unbedingt mehr Seminare anbieten, die auf dieser Einführung aufbauen und konkrete Themen vertiefen. In diesen Seminaren könnte man dann z.B. Daten modellieren oder eigene Daten erheben. Zu jedem der erwähnten Themenbereiche und Tools könnte man eigene Seminare anbieten, die in die Tiefe gehen.
Dennoch bleibt es wichtig, vorher die Grundlagen zu klären: Was ist eine Auszeichnungssprache wie HTML? Was ist XML? Was ist eine Programmiersprache? Die wenigsten wissen, was eigentlich hinter einer Webseite steckt, die sie im Internet aufrufen.
Würden Sie sagen, dass diese Skills innerhalb der eigenen Disziplin unterrichtet werden sollten oder eher fachübergreifend?
Ich denke, es ist wichtig, zunächst im Kleinen anzufangen und am eigenen Institut zu sehen, wie dort das Gefühl, der Bedarf und das Interesse für digitale Methoden sind. Wollen die Studierenden aus den Kunstwissenschaften so ein Angebot überhaupt besuchen? Ich kann Ihnen sagen: Ja. Ich habe nicht damit gerechnet, so viele Anmeldungen zu bekommen, ich musste jedes Mal einen grösseren Raum buchen.
Da ich selbst keine Kunsthistorikerin bin, sondern Germanistin, steht das Thema Interdisziplinarität sowieso im Fokus des Projekts. Die Methoden kann ich genauso gut in der Kunstgeschichte unterrichten wie in der Germanistik oder sie Historikern, Rechtswissenschaftlern oder Theologen anbieten.
Es ist mir ganz wichtig, dass sich hier ein interdisziplinäres, reziprokes Verhältnis, zunächst an der Philosophischen Fakultät, aber auch darüber hinaus entwickelt. In meiner Zusammenarbeit mit der Digital Society Initiative (DSI), die ein «Studium Digitale» vorbereitet, wird mein Einführungskurs im Herbstsemester als einer von drei Kursen pilotiert. Wir möchten sehen, wie so ein fakultätsübergreifendes Angebot mit einem eher fachorientierten Kurs, der an einem Institut angesiedelt ist, harmoniert. Zusätzlich wird der Kurs auch in der Computerlinguistik oder im Minor «Digital Humanities und Text Mining» crossgelistet.
Für den Kurs ist es sehr effizient, ein ganz heterogenes Studierendenfeld zu haben, weil die Teilnehmenden sich gegenseitig inspirieren, voneinander lernen. Einige Studierende kommen von klassischen geisteswissenschaftlichen Methoden, während andere mehr von den Daten her denken. Da verschiedene Perspektiven zusammenkommen, können ganz neue Fragestellungen entstehen.
Was verstehen Sie unter Digital Humanities?
Ich habe Ihnen dazu etwas vorbereitet: Auf der Seite whatisdigitalhumanities.com wird bei jedem Refresh ein neues Zitat zum Thema angezeigt. Mit diesen Zitaten habe ich auch versucht, meine Studierenden an das Thema heranzuführen und so die Vielseitigkeit und Divergenz deutlich zu machen. Ein gutes Beispiel dafür:
«Using digital tools to research the Humanities or using Humanities methods to research the digital.”
Das ist natürlich sehr pauschal, aber ich glaube, man muss offen sein im Umgang mit digitalen Methoden. Lässt man z.B. über fünf Romane ein Tool laufen, das Named Entity Recognition oder Topic Modeling kann (noch, bevor ich meine Fragestellung habe), dann ergeben sich mit Sicherheit Sachverhalte, mit denen man zu Beginn seiner Recherche nicht gerechnet hat. Letztlich sind das ebenso geisteswissenschaftliche Methoden, nur die Quantität ist anders, die Korpora werden grösser.
Ich denke, die digitalen Methoden unterscheiden sich letztlich gar nicht so sehr von den analogen, meine Arbeit wird durch die Hilfsmittel aber einfacher, schneller, interessanter. Das ist für mich auch der Mehrwert – dass ich grosse Mengen an Texten, Bildern und Daten untersuchen kann.
Was für ein Lehrangebot würden Sie sich wünschen?
Für mich ist es entscheidend ist, dass es auch Kurse im Bereich Digital Humanities gibt, für die keine technischen Voraussetzungen nötig sind, sonst würde man einen sehr grossen Teil der Studierenden verlieren. Deshalb wünsche ich mir ein Lehrangebot, das einerseits Grundbausteine bietet, für die keine technologischen Vorkenntnisse relevant sind. Andererseits braucht es aber auch aufbauende Module, die Themen vertiefen. Z.B. eine Übung zu digitalen Editionen, in der die Studierenden einen Text selbst in TEI konvertieren, ein XML Dokument erstellen, vielleicht sogar eine kleine Visualisierung auf einer Webseite erzeugen. Man muss die Studierenden sukzessive heranführen.
Damit Studierende lernen können, mit Daten umzugehen, bräuchte es eigentlich auch ein wenig Infrastruktur, z.B. Webserver oder Datenbanken, die über Server zugänglich sind, nicht?
Ja, das fehlt auf jeden Fall noch. Ich hoffe, dass sich so etwas in einigen Semestern etablieren lässt. Ursprünglich war auch meine Idee für den Kurs, zusammen mit den Studierenden z.B. die EasyDB des Kunsthistorischen Instituts zu nutzen und dort selbst Bilder einzuspeisen, mit Metadaten zu versehen usw. Oder wenn Studierende in einer Arbeit eine kleine Applikation entwickeln – da muss man sich überlegen, wo man diese Daten langfristig ablegt, veröffentlicht und somit nachnutzbar macht.
Möchten Sie noch etwas ansprechen, haben wir ein Thema nicht erwähnt?
Die Evaluationen der Lehrveranstaltung haben deutlich gemacht, dass es den dringenden Bedarf und den Wunsch seitens der Studierenden gibt, dieses Angebot wahrzunehmen und auszubauen.
Die Corona-Krise zeigte, wie wichtig es ist, dass man sein Lehrangebot flexibel anpassen kann. Natürlich fällt das einem Kurs wie meinem, der auf digitale Methoden abzielt wesentlich leichter, die Inhalte auch digital zu vermitteln. Viel Arbeit im laufenden Betrieb war es dennoch – das habe ich aber sehr gern in Kauf genommen.
Es geht nicht nur um digitale Forschungsmethoden, sondern eben auch um digitale Lehrformen. Es ist nicht nur die Frage, welches Konferenztool sich besser eignet, sondern auch, wo ich meine Studierenden «abhole», wie ich sie motivieren kann, zu Hause digital zu arbeiten und sie jede Woche trotzdem das Seminar online besuchen. Ich war begeistert von meinem «Corona-Kurs» und dem Ablauf im letzten Semester – das hat so gut funktioniert, es ging nichts verloren.
Man muss die Krise jetzt als Chance sehen, dieses Angebot zu erweitern. Im Herbstsemester werde ich, wenn möglich, eine Blended Learning Form wählen. Das war ursprünglich gar nicht so angedacht. Doch wir haben im Frühjahrssemester so viel Material produziert – die Studierenden haben selbst Videos erstellt und auf Switch Tube hochgeladen, in denen sie sich z.B. mit bestimmten Datenbanken beschäftigen oder digitale Editionen kritisch besprechen. Dieses riesige Potpourri an digitalem Datenmaterial muss ich jetzt einfach integrieren.
Die Dozierenden brauchen wahrscheinlich auch noch Vorbilder, Modelle, Ideen für den Unterricht…
Richtig, es braucht Hilfestellung und Support; auch auf Dozierendenseite muss die Hemmschwelle überwunden werden. Wenn es ein fakultatives Angebot bleibt, digital zu lehren (als z.B. Blended Learning oder Online-Kurs), dann, so mutmasse ich, entscheiden sich viele dagegen.
Es hat ja vielleicht damit zu tun, dass solche Hilfestellung institutionell verankert sein müsste, nicht nur didaktisch, aber auch Arbeitskraft für die technische Umsetzung – weil die einfach immer viel Zeit braucht…
Genau, und als Ergänzung dazu noch der Hinweis: Die Studierenden empfanden es als sehr problematisch, dass in jedem Kurs mit unterschiedlichen Konferenztools gearbeitet wurde. Da es schnell gehen musste, hat jeder das genutzt, was schon bekannt oder vorhanden war. Auch die Materialien waren sehr verstreut – OLAT, E-Mail, MS Teams… es ist herausfordernd für die Studierenden (aber auch uns Dozierenden), das zu kanalisieren und den Überblick zu behalten – sie haben ja nicht nur einen Kurs. Ich kenne aus einem anderen Kontext z.B. das open source Tool Big Blue Button, das sich gerade auch für Gruppenarbeiten sehr eignet, weil es eine Konferenzsoftware mit einem LMS verbindet.
Im Beitrag erwähnte Tools und Links:
https://www.swissuniversities.ch/themen/digitalisierung/digital-skills
https://transkribus.eu/Transkribus/
https://github.com/OCR4all/LAREX
https://de.wikipedia.org/wiki/Text_Encoding_Initiative
https://de.wikipedia.org/wiki/Linked_Open_Data
https://de.wikipedia.org/wiki/Easydb
http://whatisdigitalhumanities.com/
https://en.wikipedia.org/wiki/Topic_model